 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid Training of Very Large Ensembles of Diverse Neural Networks
Paper and Code
Sep 12, 2018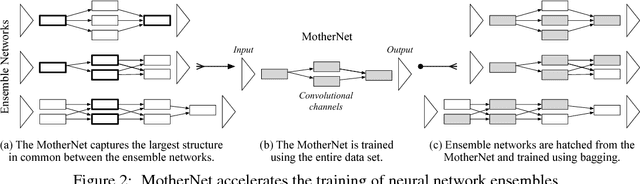
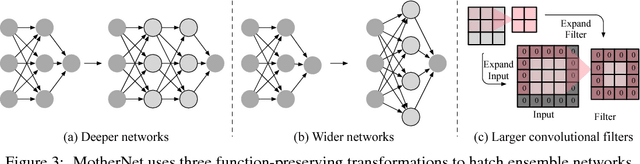
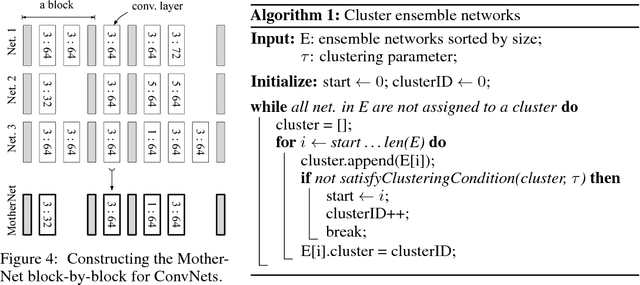
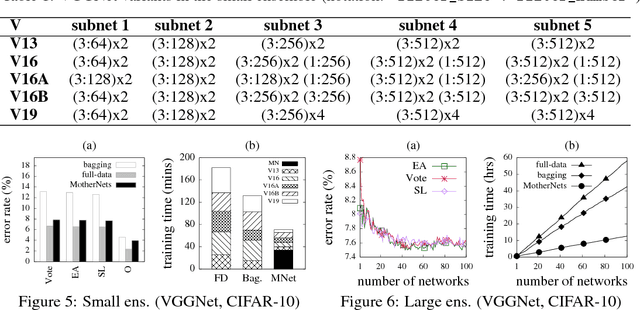
Ensembles of deep neural networks with diverse architectures significantly improve generalization accuracy. However, training such ensembles requires a large amount of computational resources and time as every network in the ensemble has to be separately trained. In practice, this restricts the number of different deep neural network architectures that can be included within an ensemble. We propose a new approach to address this problem. Our approach captures the structural similarity between members of a neural network ensemble and train it only once. Subsequently, this knowledge is transferred to all members of the ensemble using function-preserving transformations. Then, these ensemble networks converge significantly faster as compared to training from scratch. We show through experiments on CIFAR-10, CIFAR-100, and SVHN data sets that our approach can train large and diverse ensembles of deep neural networks achieving comparable accuracy to existing approaches in a fraction of their training time. In particular, our approach trains an ensemble of $100$ variants of deep neural networks with diverse architectures up to $6 \times$ faster as compared to existing approaches. This improvement in training cost grows linearly with the size of the ensemble.