 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid-Rate: A Framework for Semi-supervised Real-time Sentiment Trend Detection in Unstructured Big Data
Paper and Code
Mar 25, 2017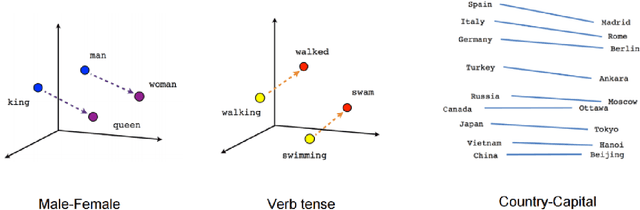
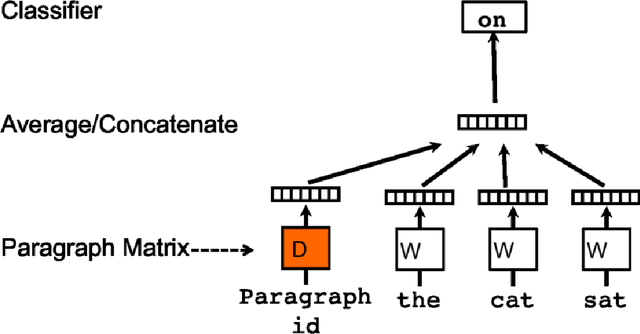
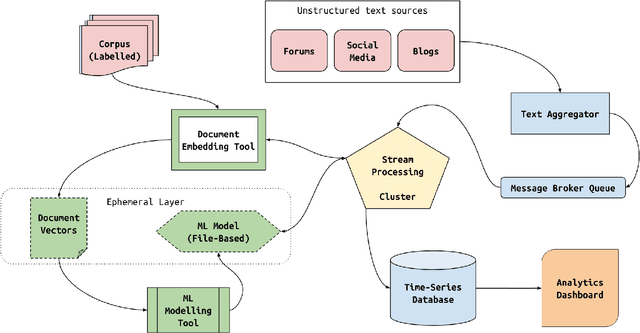
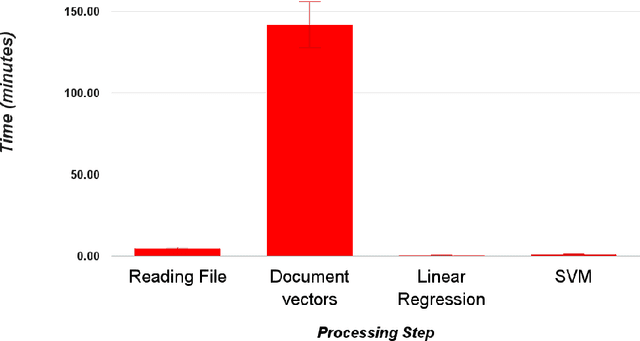
Commercial establishments like restaurants, service centres and retailers have several sources of customer feedback about products and services, most of which need not be as structured as rated reviews provided by services like Yelp, or Amazon, in terms of sentiment conveyed. For instance, Amazon provides a fine-grained score on a numeric scale for product reviews. Some sources, however, like social media (Twitter, Facebook), mailing lists (Google Groups) and forums (Quora) contain text data that is much more voluminous, but unstructured and unlabelled. It might be in the best interests of a business establishment to assess the general sentiment towards their brand on these platforms as well. This text could be pipelined into a system with a built-in prediction model, with the objective of generating real-time graphs on opinion and sentiment trends. Although such tasks like the one described about have been explored with respect to document classification problems in the past, the implementation described in this paper, by virtue of learning a continuous function rather than a discrete one, offers a lot more depth of insight as compared to document classification approaches. This study aims to explore the validity of such a continuous function predicting model to quantify sentiment about an entity, without the additional overhead of manual labelling, and computational preprocessing & feature extraction. This research project also aims to design and implement a re-usable document regression pipeline as a framework, Rapid-Rate, that can be used to predict document scores in real-time.