 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Relabeling for Efficient Machine Unlearning
Paper and Code
May 21, 2023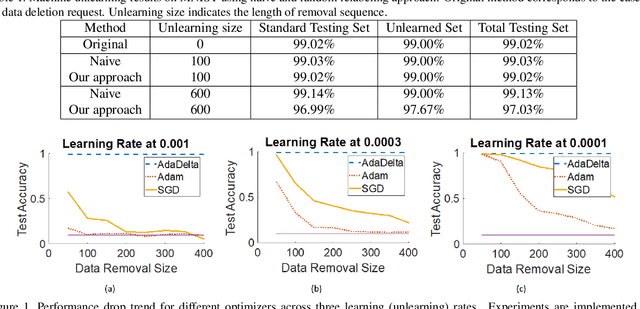
Learning algorithms and data are the driving forces for machine learning to bring about tremendous transformation of industrial intelligence. However, individuals' right to retract their personal data and relevant data privacy regulations pose great challenges to machine learning: how to design an efficient mechanism to support certified data removals. Removal of previously seen data known as machine unlearning is challenging as these data points were implicitly memorized in training process of learning algorithms. Retraining remaining data from scratch straightforwardly serves such deletion requests, however, this naive method is not often computationally feasible. We propose the unlearning scheme random relabeling, which is applicable to generic supervised learning algorithms, to efficiently deal with sequential data removal requests in the online setting. A less constraining removal certification method based on probability distribution similarity with naive unlearning is further developed for logit-based classifiers.