 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestion Relevance in Visual Question Answering
Paper and Code
Jul 23, 2018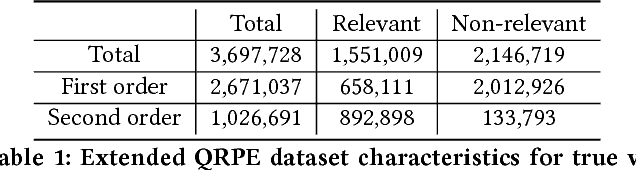


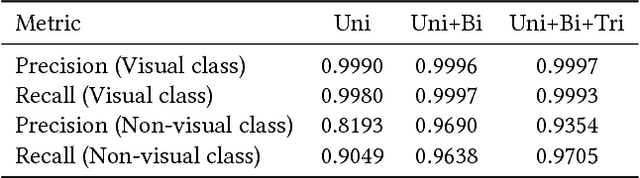
Free-form and open-ended Visual Question Answering systems solve the problem of providing an accurate natural language answer to a question pertaining to an image. Current VQA systems do not evaluate if the posed question is relevant to the input image and hence provide nonsensical answers when posed with irrelevant questions to an image. In this paper, we solve the problem of identifying the relevance of the posed question to an image. We address the problem as two sub-problems. We first identify if the question is visual or not. If the question is visual, we then determine if it's relevant to the image or not. For the second problem, we generate a large dataset from existing visual question answering datasets in order to enable the training of complex architectures and model the relevance of a visual question to an image. We also compare the results of our Long Short-Term Memory Recurrent Neural Network based models to Logistic Regression, XGBoost and multi-layer perceptron based approaches to the problem.