 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestion Embeddings Based on Shannon Entropy: Solving intent classification task in goal-oriented dialogue system
Paper and Code
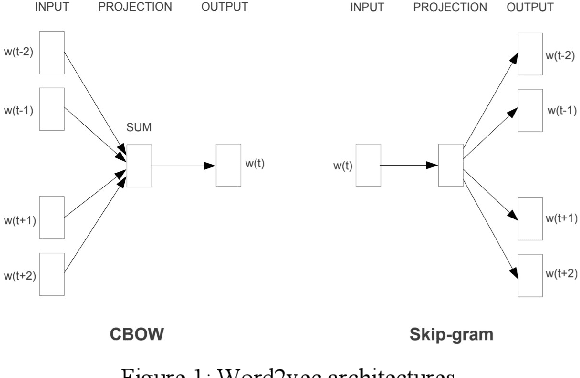
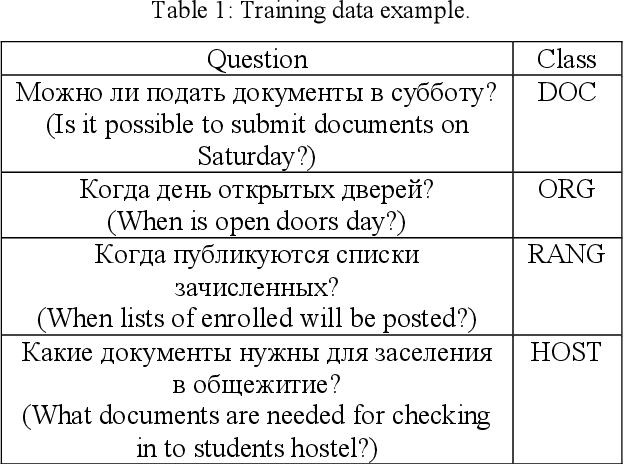
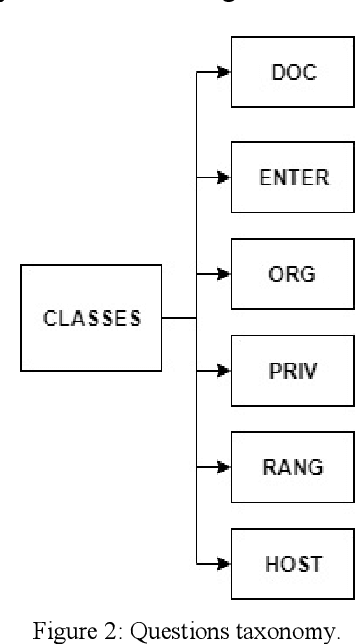
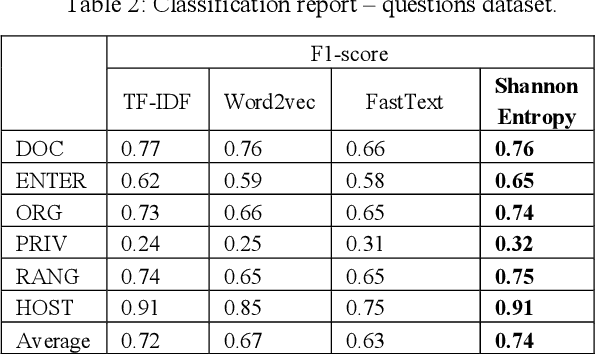
Question-answering systems and voice assistants are becoming major part of client service departments of many organizations, helping them to reduce the labor costs of staff. In many such systems, there is always natural language understanding module that solves intent classification task. This task is complicated because of its case-dependency - every subject area has its own semantic kernel. The state of art approaches for intent classification are different machine learning and deep learning methods that use text vector representations as input. The basic vector representation models such as Bag of words and TF-IDF generate sparse matrixes, which are becoming very big as the amount of input data grows. Modern methods such as word2vec and FastText use neural networks to evaluate word embeddings with fixed dimension size. As we are developing a question-answering system for students and enrollees of the Perm National Research Polytechnic University, we have faced the problem of user's intent detection. The subject area of our system is very specific, that is why there is a lack of training data. This aspect makes intent classification task more challenging for using state of the art deep learning methods. In this paper, we propose an approach of the questions embeddings representation based on calculation of Shannon entropy.The goal of the approach is to produce low dimensional question vectors as neural approaches do and to outperform related methods, described above in condition of small dataset. We evaluate and compare our model with existing ones using logistic regression and dataset that contains questions asked by students and enrollees. The data is labeled into six classes. Experimental comparison of proposed approach and other models revealed that proposed model performed better in the given task.