 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuaternion Capsule Networks
Paper and Code
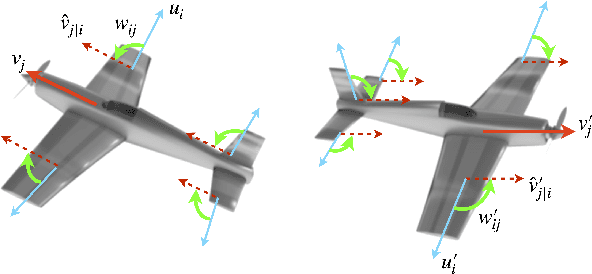
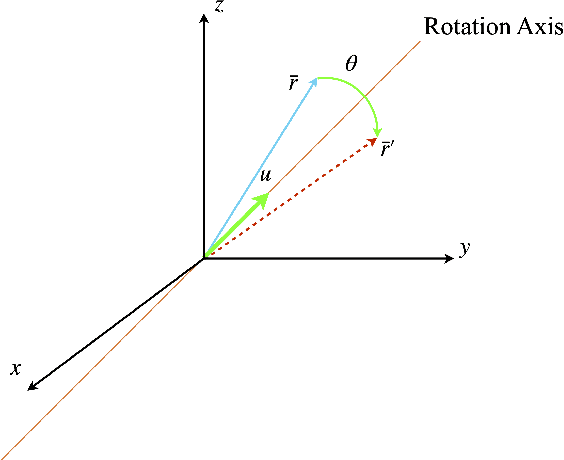
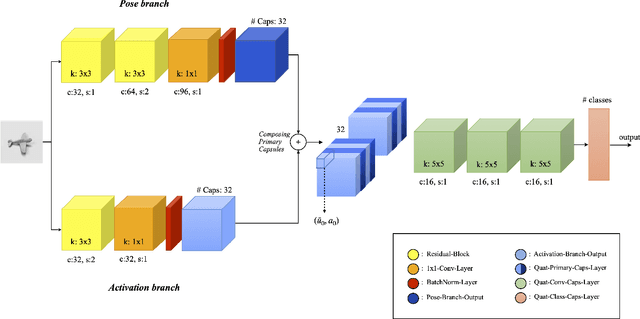
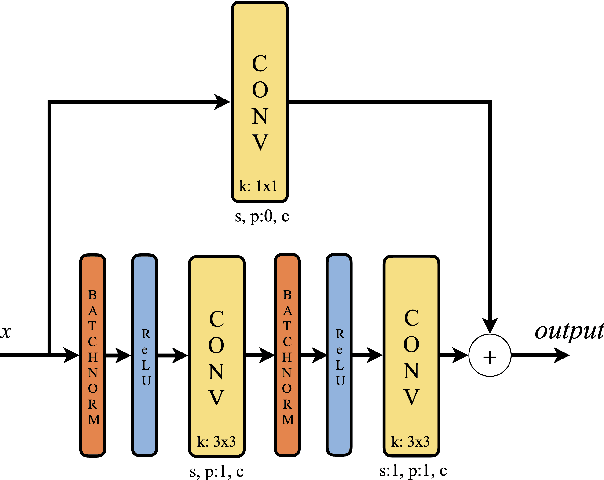
Capsules are grouping of neurons that allow to represent sophisticated information of a visual entity such as pose and features. In the view of this property, Capsule Networks outperform CNNs in challenging tasks like object recognition in unseen viewpoints, and this is achieved by learning the transformations between the object and its parts with the help of high dimensional representation of pose information. In this paper, we present Quaternion Capsules (QCN) where pose information of capsules and their transformations are represented by quaternions. Quaternions are immune to the gimbal lock, have straightforward regularization of the rotation representation for capsules, and require less number of parameters than matrices. The experimental results show that QCNs generalize better to novel viewpoints with fewer parameters, and also achieve on-par or better performances with the state-of-the-art Capsule architectures on well-known benchmarking datasets.