 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning and Sparsemax Methods for Hierarchical Attention Networks
Paper and Code
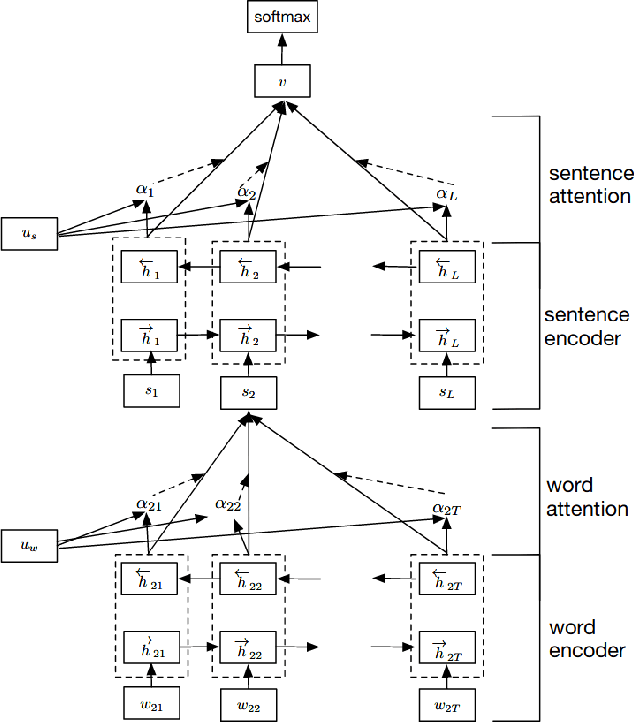
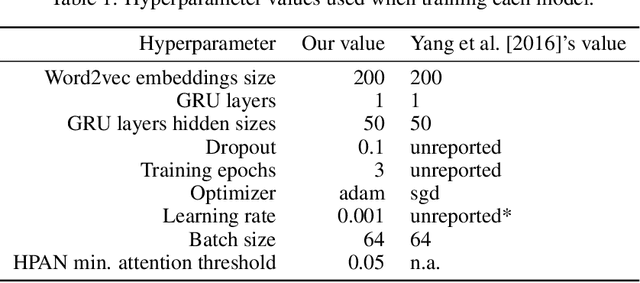
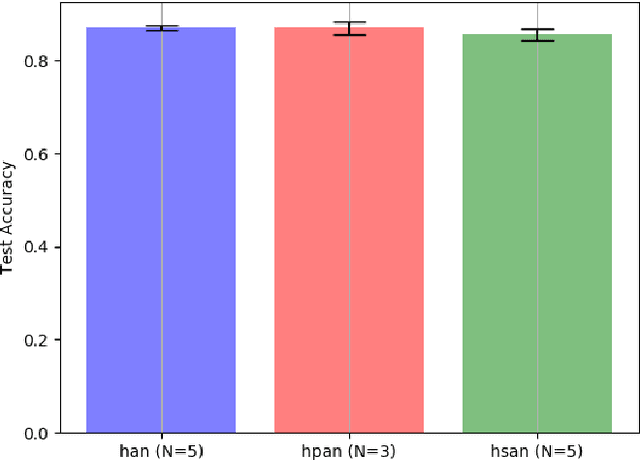

This paper introduces and evaluates two novel Hierarchical Attention Network models [Yang et al., 2016] - i) Hierarchical Pruned Attention Networks, which remove the irrelevant words and sentences from the classification process in order to reduce potential noise in the document classification accuracy and ii) Hierarchical Sparsemax Attention Networks, which replace the Softmax function used in the attention mechanism with the Sparsemax [Martins and Astudillo, 2016], capable of better handling importance distributions where a lot of words or sentences have very low probabilities. Our empirical evaluation on the IMDB Review for sentiment analysis datasets shows both approaches to be able to match the results obtained by the current state-of-the-art (without, however, any significant benefits). All our source code is made available athttps://github.com/jmribeiro/dsl-project.