 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably More Efficient Q-Learning in the Full-Feedback/One-Sided-Feedback Settings
Paper and Code
Jun 30, 2020
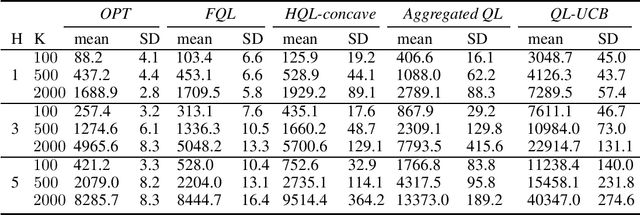
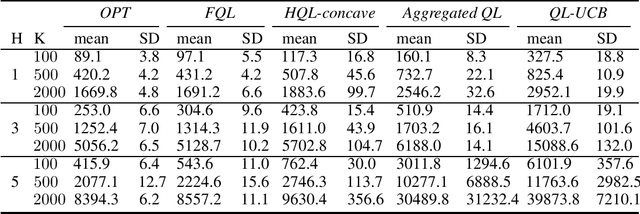
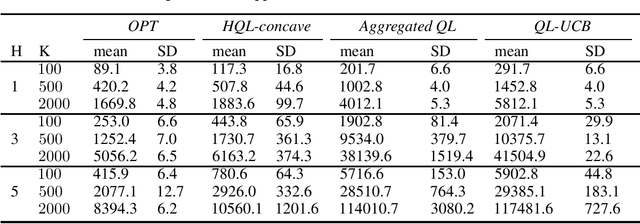
We propose two new Q-learning algorithms, Full-Q-Learning (FQL) and Elimination-Based Half-Q-Learning (HQL), that enjoy improved efficiency and optimality in the full-feedback and the one-sided-feedback settings over existing Q-learning algorithms. We establish that FQL incurs regret $\tilde{O}(H^2\sqrt{ T})$ and HQL incurs regret $ \tilde{O}(H^3\sqrt{ T})$, where $H$ is the length of each episode and $T$ is the total number of time periods. Our regret bounds are not affected by the possibly huge state and action space. Our numerical experiments using the classical inventory control problem as an example demonstrate the superior efficiency of FQL and HQL, and shows the potential of tailoring reinforcement learning algorithms for richer feedback models, which are prevalent in many natural problems.