 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Modelling of Morphologically Rich Languages
Paper and Code
Aug 18, 2015


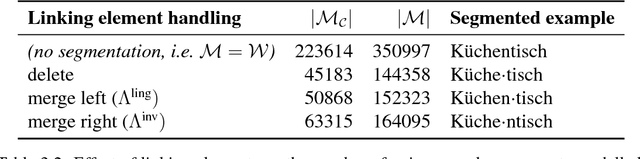
This thesis investigates how the sub-structure of words can be accounted for in probabilistic models of language. Such models play an important role in natural language processing tasks such as translation or speech recognition, but often rely on the simplistic assumption that words are opaque symbols. This assumption does not fit morphologically complex language well, where words can have rich internal structure and sub-word elements are shared across distinct word forms. Our approach is to encode basic notions of morphology into the assumptions of three different types of language models, with the intention that leveraging shared sub-word structure can improve model performance and help overcome data sparsity that arises from morphological processes. In the context of n-gram language modelling, we formulate a new Bayesian model that relies on the decomposition of compound words to attain better smoothing, and we develop a new distributed language model that learns vector representations of morphemes and leverages them to link together morphologically related words. In both cases, we show that accounting for word sub-structure improves the models' intrinsic performance and provides benefits when applied to other tasks, including machine translation. We then shift the focus beyond the modelling of word sequences and consider models that automatically learn what the sub-word elements of a given language are, given an unannotated list of words. We formulate a novel model that can learn discontiguous morphemes in addition to the more conventional contiguous morphemes that most previous models are limited to. This approach is demonstrated on Semitic languages, and we find that modelling discontiguous sub-word structures leads to improvements in the task of segmenting words into their contiguous morphemes.