 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-training Attention Mechanisms
Paper and Code
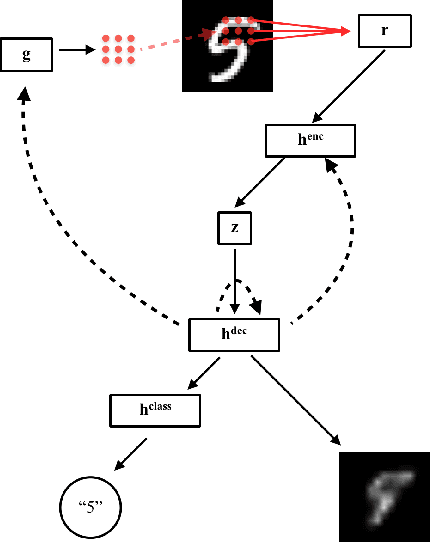



Recurrent neural networks with differentiable attention mechanisms have had success in generative and classification tasks. We show that the classification performance of such models can be enhanced by guiding a randomly initialized model to attend to salient regions of the input in early training iterations. We further show that, if explicit heuristics for guidance are unavailable, a model that is pretrained on an unsupervised reconstruction task can discover good attention policies without supervision. We demonstrate that increased efficiency of the attention mechanism itself contributes to these performance improvements. Based on these insights, we introduce bootstrapped glimpse mimicking, a simple, theoretically task-general method of more effectively training attention models. Our work draws inspiration from and parallels results on human learning of attention.