Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Invariance under Reward Transformations for General-Sum Stochastic Games
Paper and Code
Jan 16, 2014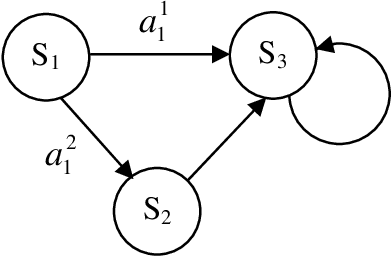
We extend the potential-based shaping method from Markov decision processes to multi-player general-sum stochastic games. We prove that the Nash equilibria in a stochastic game remains unchanged after potential-based shaping is applied to the environment. The property of policy invariance provides a possible way of speeding convergence when learning to play a stochastic game.
* Journal Of Artificial Intelligence Research, Volume 41, pages
397-406, 2011
View paper on