 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePipeSim: Trace-driven Simulation of Large-Scale AI Operations Platforms
Paper and Code
Jun 22, 2020
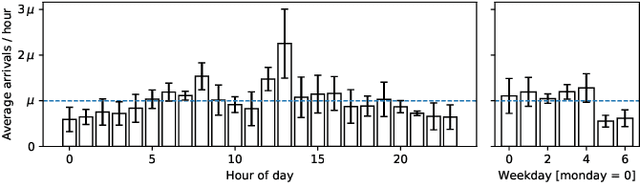
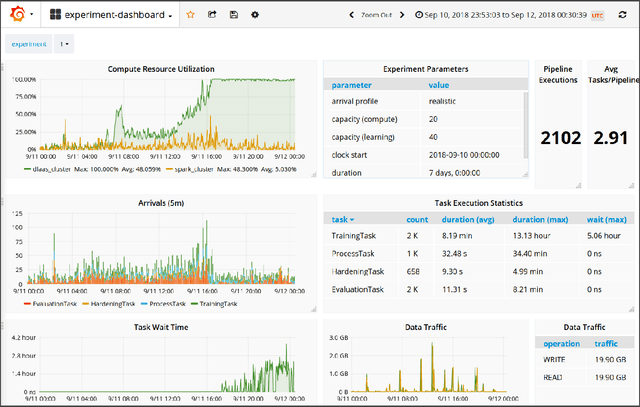

Operationalizing AI has become a major endeavor in both research and industry. Automated, operationalized pipelines that manage the AI application lifecycle will form a significant part of tomorrow's infrastructure workloads. To optimize operations of production-grade AI workflow platforms we can leverage existing scheduling approaches, yet it is challenging to fine-tune operational strategies that achieve application-specific cost-benefit tradeoffs while catering to the specific domain characteristics of machine learning (ML) models, such as accuracy, robustness, or fairness. We present a trace-driven simulation-based experimentation and analytics environment that allows researchers and engineers to devise and evaluate such operational strategies for large-scale AI workflow systems. Analytics data from a production-grade AI platform developed at IBM are used to build a comprehensive simulation model. Our simulation model describes the interaction between pipelines and system infrastructure, and how pipeline tasks affect different ML model metrics. We implement the model in a standalone, stochastic, discrete event simulator, and provide a toolkit for running experiments. Synthetic traces are made available for ad-hoc exploration as well as statistical analysis of experiments to test and examine pipeline scheduling, cluster resource allocation, and similar operational mechanisms.