 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhoneme Segmentation Using Self-Supervised Speech Models
Paper and Code

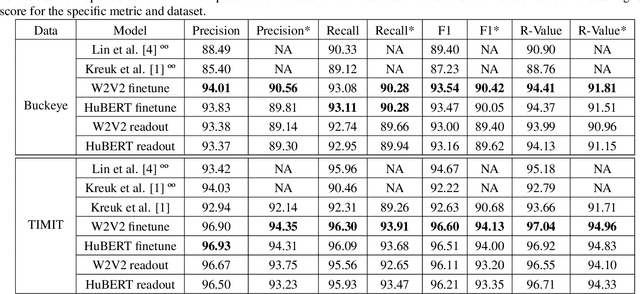


We apply transfer learning to the task of phoneme segmentation and demonstrate the utility of representations learned in self-supervised pre-training for the task. Our model extends transformer-style encoders with strategically placed convolutions that manipulate features learned in pre-training. Using the TIMIT and Buckeye corpora we train and test the model in the supervised and unsupervised settings. The latter case is accomplished by furnishing a noisy label-set with the predictions of a separate model, it having been trained in an unsupervised fashion. Results indicate our model eclipses previous state-of-the-art performance in both settings and on both datasets. Finally, following observations during published code review and attempts to reproduce past segmentation results, we find a need to disambiguate the definition and implementation of widely-used evaluation metrics. We resolve this ambiguity by delineating two distinct evaluation schemes and describing their nuances.