 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Video Summarization by Multimodal Video Understanding
Paper and Code
Nov 05, 2024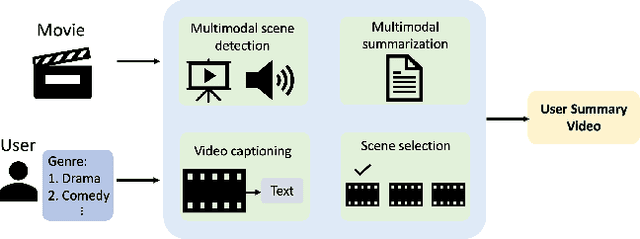

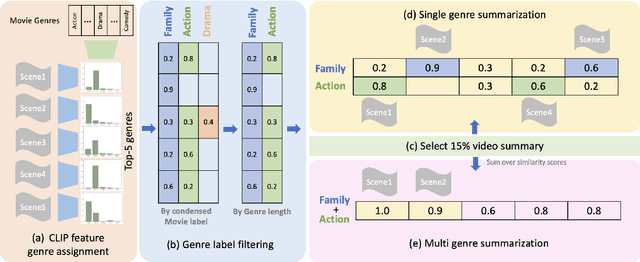

Video summarization techniques have been proven to improve the overall user experience when it comes to accessing and comprehending video content. If the user's preference is known, video summarization can identify significant information or relevant content from an input video, aiding them in obtaining the necessary information or determining their interest in watching the original video. Adapting video summarization to various types of video and user preferences requires significant training data and expensive human labeling. To facilitate such research, we proposed a new benchmark for video summarization that captures various user preferences. Also, we present a pipeline called Video Summarization with Language (VSL) for user-preferred video summarization that is based on pre-trained visual language models (VLMs) to avoid the need to train a video summarization system on a large training dataset. The pipeline takes both video and closed captioning as input and performs semantic analysis at the scene level by converting video frames into text. Subsequently, the user's genre preference was used as the basis for selecting the pertinent textual scenes. The experimental results demonstrate that our proposed pipeline outperforms current state-of-the-art unsupervised video summarization models. We show that our method is more adaptable across different datasets compared to supervised query-based video summarization models. In the end, the runtime analysis demonstrates that our pipeline is more suitable for practical use when scaling up the number of user preferences and videos.