 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Decentralized Bilevel Optimization over Stochastic and Directed Networks
Paper and Code
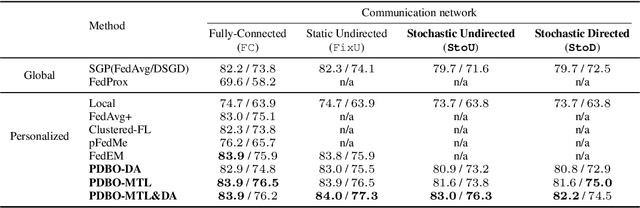
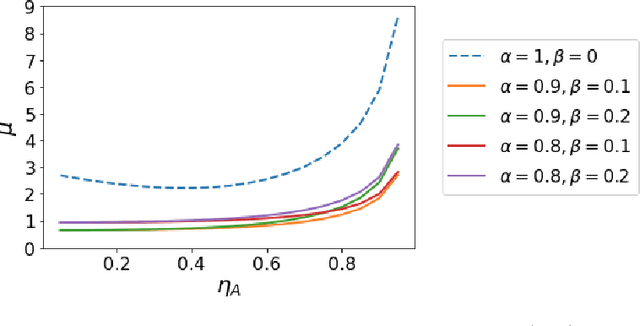

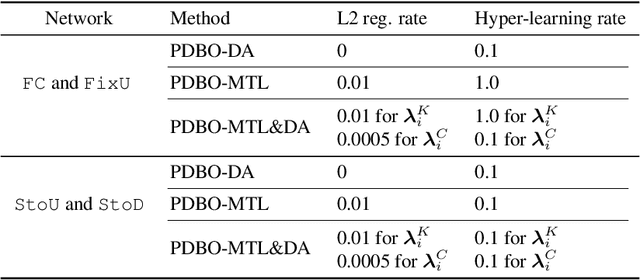
While personalization in distributed learning has been extensively studied, existing approaches employ dedicated algorithms to optimize their specific type of parameters (e.g., client clusters or model interpolation weights), making it difficult to simultaneously optimize different types of parameters to yield better performance. Moreover, their algorithms require centralized or static undirected communication networks, which can be vulnerable to center-point failures or deadlocks. This study proposes optimizing various types of parameters using a single algorithm that runs on more practical communication environments. First, we propose a gradient-based bilevel optimization that reduces most personalization approaches to the optimization of client-wise hyperparameters. Second, we propose a decentralized algorithm to estimate gradients with respect to the hyperparameters, which can run even on stochastic and directed communication networks. Our empirical results demonstrated that the gradient-based bilevel optimization enabled combining existing personalization approaches which led to state-of-the-art performance, confirming it can perform on multiple simulated communication environments including a stochastic and directed network.