 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Optimization on Model Synchronization in Parallel Stochastic Gradient Descent Based SVM
Paper and Code
May 03, 2019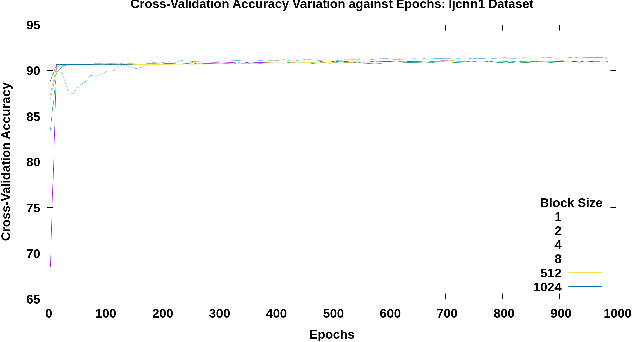
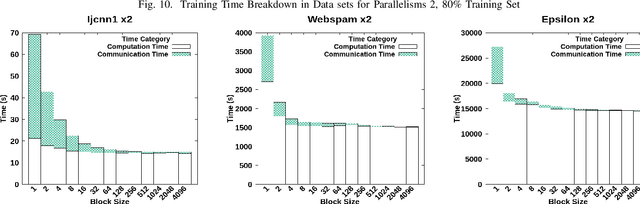
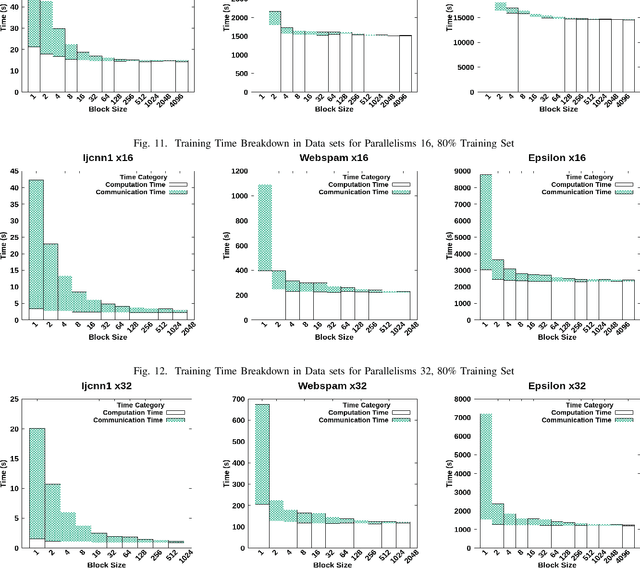
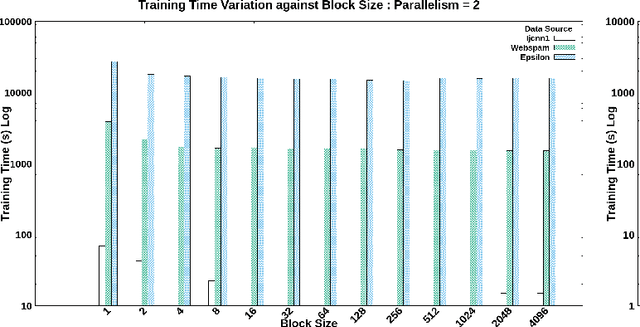
Understanding the bottlenecks in implementing stochastic gradient descent (SGD)-based distributed support vector machines (SVM) algorithm is important in training larger data sets. The communication time to do the model synchronization across the parallel processes is the main bottleneck that causes inefficiency in the training process. The model synchronization is directly affected by the mini-batch size of data processed before the global synchronization. In producing an efficient distributed model, the communication time in training model synchronization has to be as minimum as possible while retaining a high testing accuracy. The effect from model synchronization frequency over the convergence of the algorithm and accuracy of the generated model must be well understood to design an efficient distributed model. In this research, we identify the bottlenecks in model synchronization in parallel stochastic gradient descent (PSGD)-based SVM algorithm with respect to the training model synchronization frequency (MSF). Our research shows that by optimizing the MSF in the data sets that we used, a reduction of 98\% in communication time can be gained (16x - 24x speed up) with respect to high-frequency model synchronization. The training model optimization discussed in this paper guarantees a higher accuracy than the sequential algorithm along with faster convergence.