 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptual Gradient Networks
Paper and Code
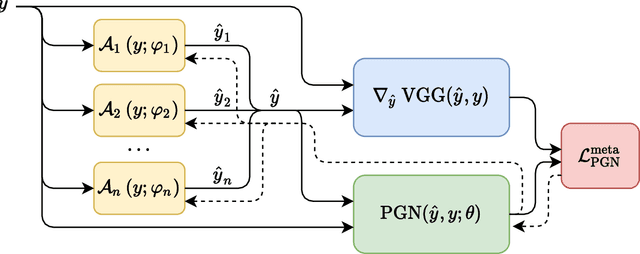
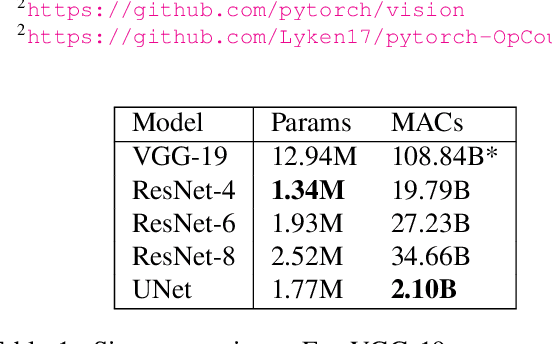
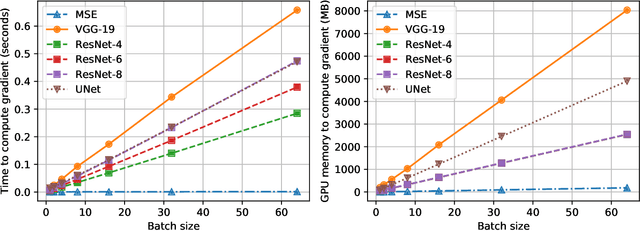
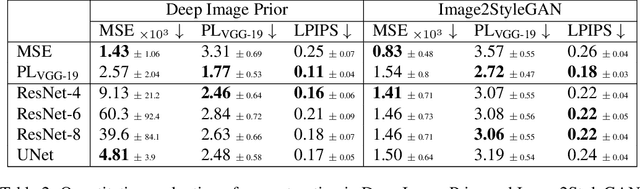
Many applications of deep learning for image generation use perceptual losses for either training or fine-tuning of the generator networks. The use of perceptual loss however incurs repeated forward-backward passes in a large image classification network as well as a considerable memory overhead required to store the activations of this network. It is therefore desirable or sometimes even critical to get rid of these overheads. In this work, we propose a way to train generator networks using approximations of perceptual loss that are computed without forward-backward passes. Instead, we use a simpler perceptual gradient network that directly synthesizes the gradient field of a perceptual loss. We introduce the concept of proxy targets, which stabilize the predicted gradient, meaning that learning with it does not lead to divergence or oscillations. In addition, our method allows interpretation of the predicted gradient, providing insight into the internals of perceptual loss and suggesting potential ways to improve it in future work.