 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgepdfPapers: shell-script utilities for frequency-based multi-word phrase extraction from PDF documents
Paper and Code
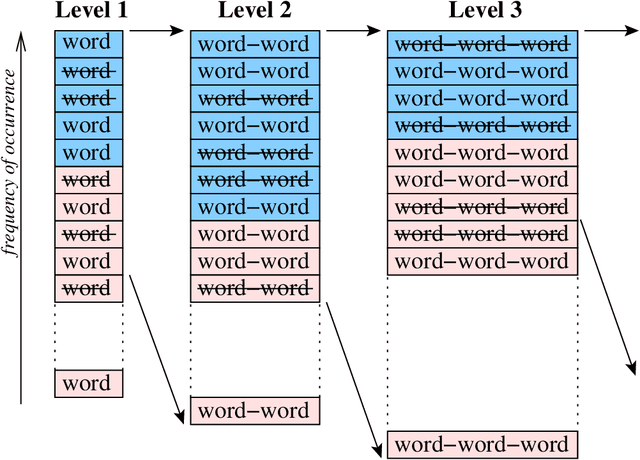
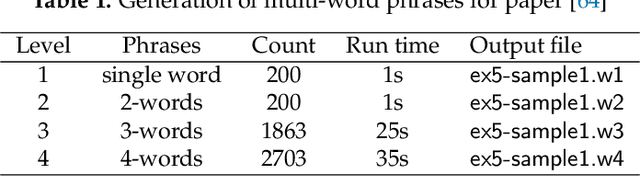
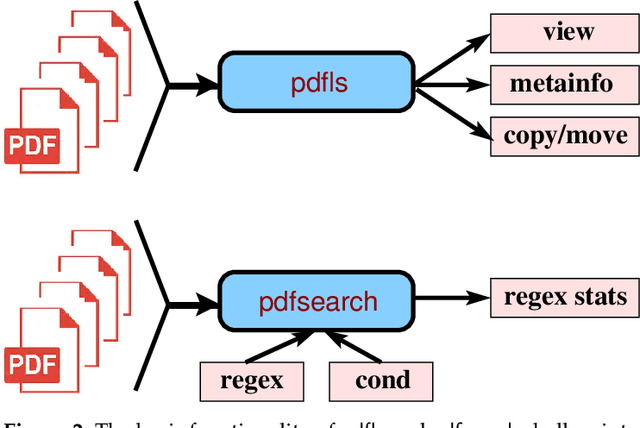
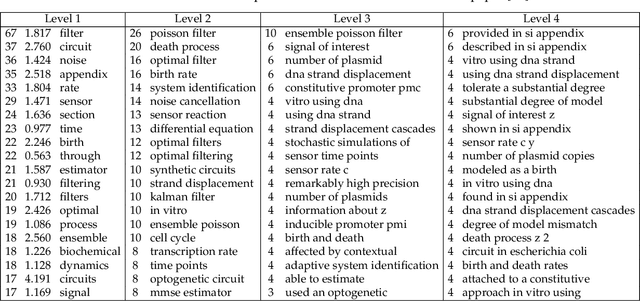
Biomedical research is intensive in processing information in the previously published papers. This motivated a lot of efforts to provide tools for text mining and information extraction from PDF documents over the past decade. The *nix (Unix/Linux) operating systems offer many tools for working with text files, however, very few such tools are available for processing the contents of PDF files. This paper reports our effort to develop shell script utilities for *nix systems with the core functionality focused on viewing and searching multiple PDF documents combining logical and regular expressions, and enabling more reliable text extraction from PDF documents with subsequent manipulation of the resulting blocks of text. Furthermore, a procedure for extracting the most frequently occurring multi-word phrases was devised and then demonstrated on several scientific papers in life sciences. Our experiments revealed that the procedure is surprisingly robust to deficiencies in text extraction and the actual scoring function used to rank the phrases in terms of their importance or relevance. The keyword relevance is strongly context dependent, the word stemming did not provide any recognizable advantage, and the stop-words should only be removed from the beginning and the end of phrases. In addition, the developed utilities were used to convert the list of acronyms and the index from a PDF e-book into a large list of biochemical terms which can be exploited in other text mining tasks. All shell scripts and data files are available in a public repository named \pp\ on the Github. The key lesson learned in this work is that semi-automated methods combining the power of algorithms with the capabilities of research experience are the most promising for improving the research efficiency.