 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParser Extraction of Triples in Unstructured Text
Paper and Code
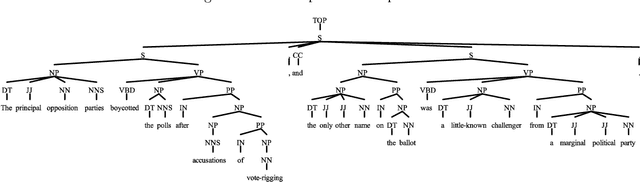

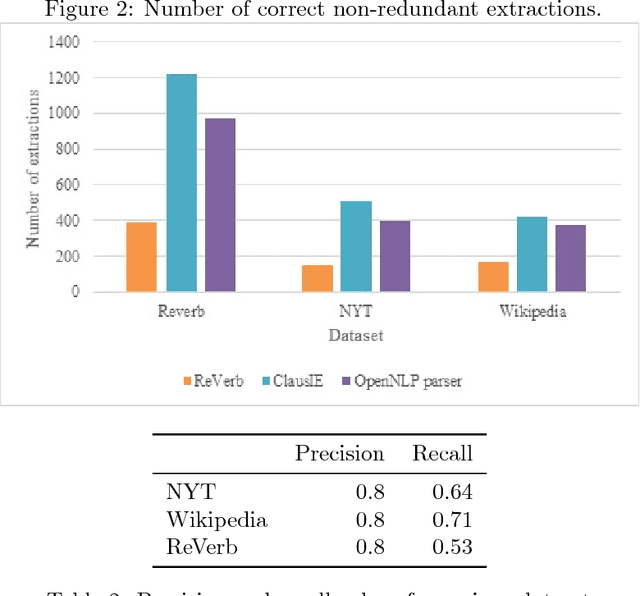
The web contains vast repositories of unstructured text. We investigate the opportunity for building a knowledge graph from these text sources. We generate a set of triples which can be used in knowledge gathering and integration. We define the architecture of a language compiler for processing subject-predicate-object triples using the OpenNLP parser. We implement a depth-first search traversal on the POS tagged syntactic tree appending predicate and object information. A parser enables higher precision and higher recall extractions of syntactic relationships across conjunction boundaries. We are able to extract 2-2.5 times the correct extractions of ReVerb. The extractions are used in a variety of semantic web applications and question answering. We verify extraction of 50,000 triples on the ClueWeb dataset.