 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParenting: Safe Reinforcement Learning from Human Input
Paper and Code
Feb 18, 2019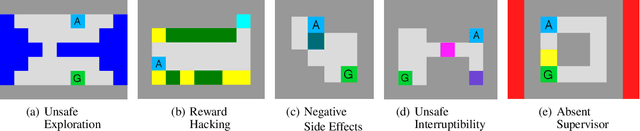
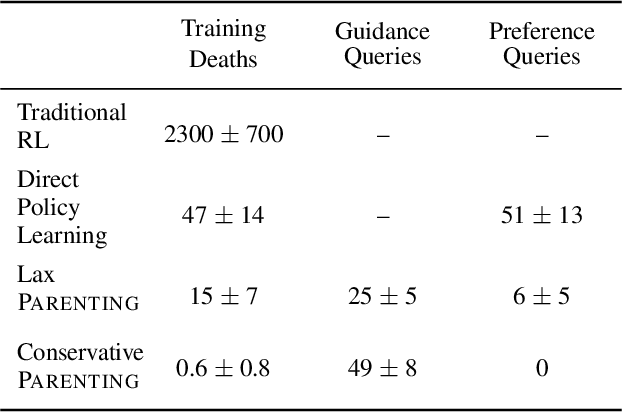
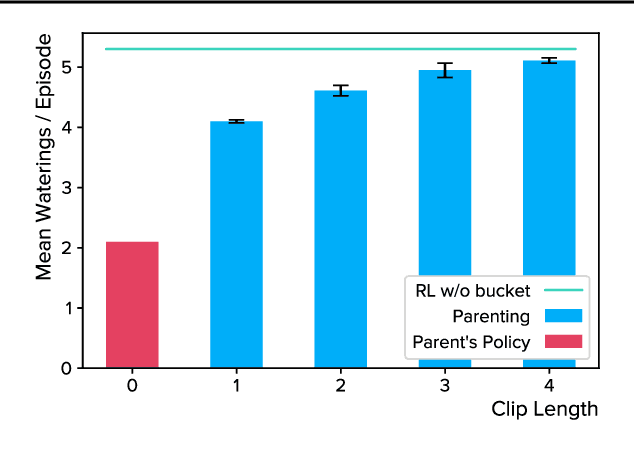
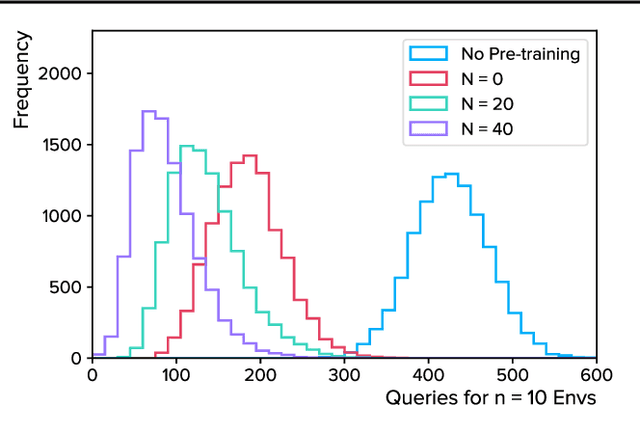
Autonomous agents trained via reinforcement learning present numerous safety concerns: reward hacking, negative side effects, and unsafe exploration, among others. In the context of near-future autonomous agents, operating in environments where humans understand the existing dangers, human involvement in the learning process has proved a promising approach to AI Safety. Here we demonstrate that a precise framework for learning from human input, loosely inspired by the way humans parent children, solves a broad class of safety problems in this context. We show that our Parenting algorithm solves these problems in the relevant AI Safety gridworlds of Leike et al. (2017), that an agent can learn to outperform its parent as it "matures", and that policies learnt through Parenting are generalisable to new environments.