 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOversampling for Imbalanced Time Series Data
Paper and Code
Apr 14, 2020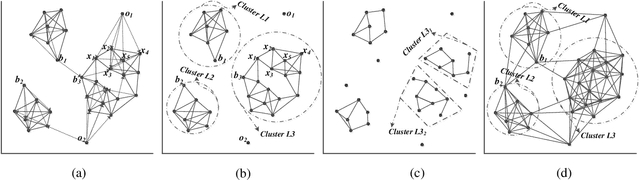
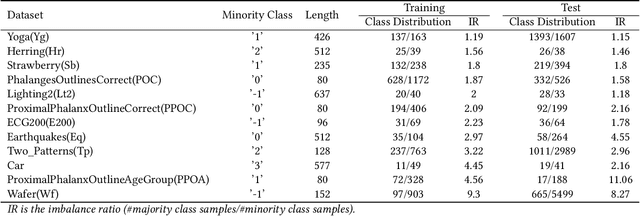
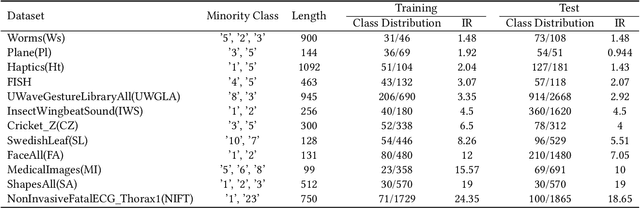
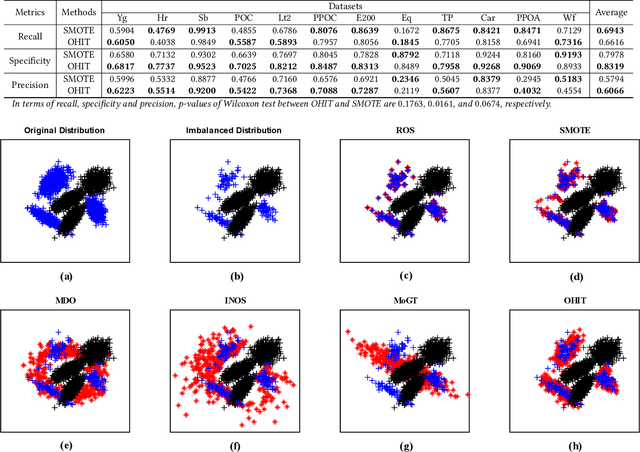
Many important real-world applications involve time-series data with skewed distribution. Compared to conventional imbalance learning problems, the classification of imbalanced time-series data is more challenging due to high dimensionality and high inter-variable correlation. This paper proposes a structure preserving Oversampling method to combat the High-dimensional Imbalanced Time-series classification (OHIT). OHIT first leverages a density-ratio based shared nearest neighbor clustering algorithm to capture the modes of minority class in high-dimensional space. It then for each mode applies the shrinkage technique of large-dimensional covariance matrix to obtain accurate and reliable covariance structure. Finally, OHIT generates the structure-preserving synthetic samples based on multivariate Gaussian distribution by using the estimated covariance matrices. Experimental results on several publicly available time-series datasets (including unimodal and multi-modal) demonstrate the superiority of OHIT against the state-of-the-art oversampling algorithms in terms of F-value, G-mean, and AUC.