 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Overfitting and Large Weight Update Problem in Linear Rectifiers: Thresholded Exponential Rectified Linear Units
Paper and Code
Jun 04, 2020
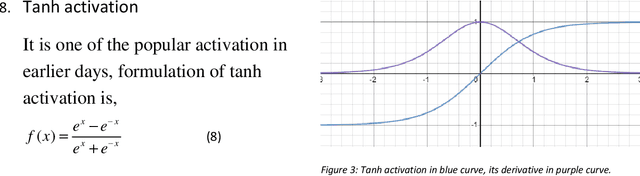
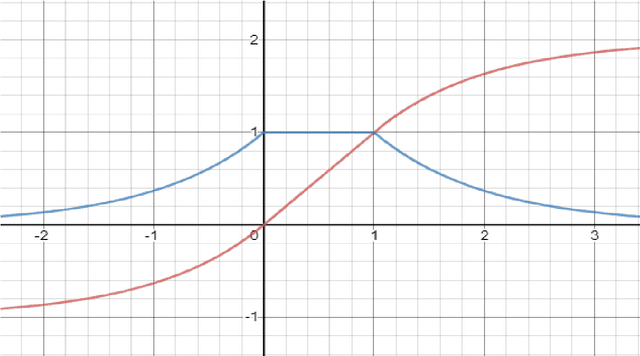
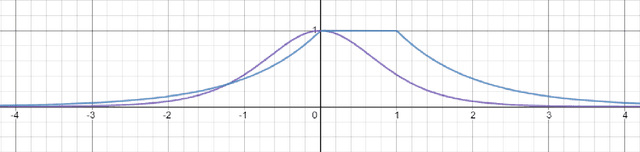
In past few years, linear rectified unit activation functions have shown its significance in the neural networks, surpassing the performance of sigmoid activations. RELU (Nair & Hinton, 2010), ELU (Clevert et al., 2015), PRELU (He et al., 2015), LRELU (Maas et al., 2013), SRELU (Jin et al., 2016), ThresholdedRELU, all these linear rectified activation functions have its own significance over others in some aspect. Most of the time these activation functions suffer from bias shift problem due to non-zero output mean, and high weight update problem in deep complex networks due to unit gradient, which results in slower training, and high variance in model prediction respectively. In this paper, we propose, "Thresholded exponential rectified linear unit" (TERELU) activation function that works better in alleviating in overfitting: large weight update problem. Along with alleviating overfitting problem, this method also gives good amount of non-linearity as compared to other linear rectifiers. We will show better performance on the various datasets using neural networks, considering TERELU activation method compared to other activations.