 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Shot Multilingual Font Generation Via ViT
Paper and Code
Dec 15, 2024
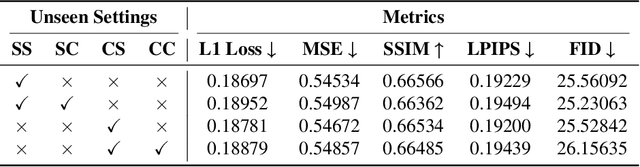

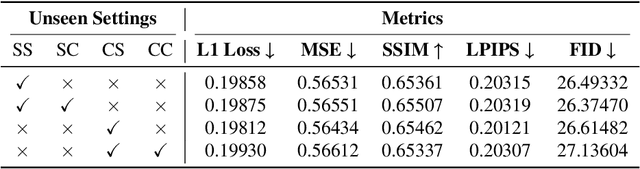
Font design poses unique challenges for logographic languages like Chinese, Japanese, and Korean (CJK), where thousands of unique characters must be individually crafted. This paper introduces a novel Vision Transformer (ViT)-based model for multi-language font generation, effectively addressing the complexities of both logographic and alphabetic scripts. By leveraging ViT and pretraining with a strong visual pretext task (Masked Autoencoding, MAE), our model eliminates the need for complex design components in prior frameworks while achieving comprehensive results with enhanced generalizability. Remarkably, it can generate high-quality fonts across multiple languages for unseen, unknown, and even user-crafted characters. Additionally, we integrate a Retrieval-Augmented Guidance (RAG) module to dynamically retrieve and adapt style references, improving scalability and real-world applicability. We evaluated our approach in various font generation tasks, demonstrating its effectiveness, adaptability, and scalability.