 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Shot Free-View Neural Talking-Head Synthesis for Video Conferencing
Paper and Code

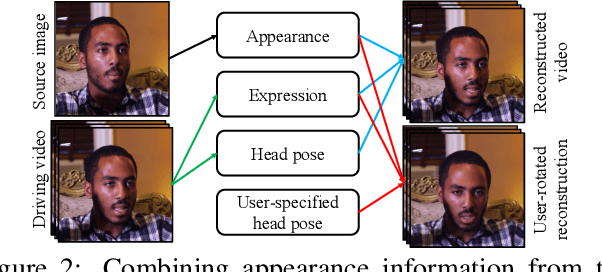

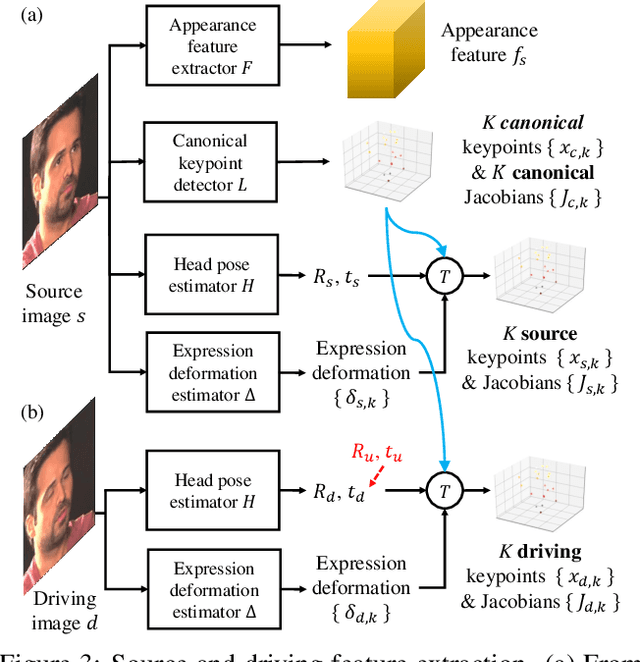
We propose a neural talking-head video synthesis model and demonstrate its application to video conferencing. Our model learns to synthesize a talking-head video using a source image containing the target person's appearance and a driving video that dictates the motion in the output. Our motion is encoded based on a novel keypoint representation, where the identity-specific and motion-related information is decomposed unsupervisedly. Extensive experimental validation shows that our model outperforms competing methods on benchmark datasets. Moreover, our compact keypoint representation enables a video conferencing system that achieves the same visual quality as the commercial H.264 standard while only using one-tenth of the bandwidth. Besides, we show our keypoint representation allows the user to rotate the head during synthesis, which is useful for simulating a face-to-face video conferencing experience.