 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Use of Linguistic Features for the Evaluation of Generative Dialogue Systems
Paper and Code
Apr 13, 2021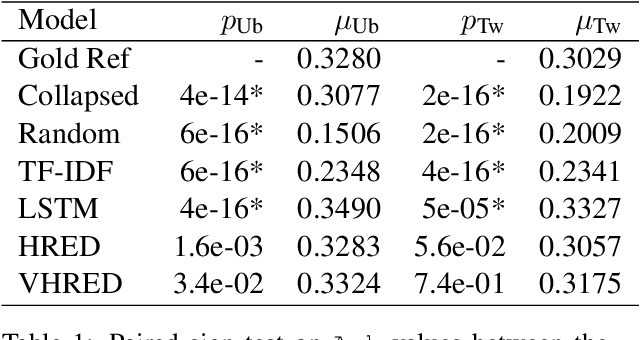
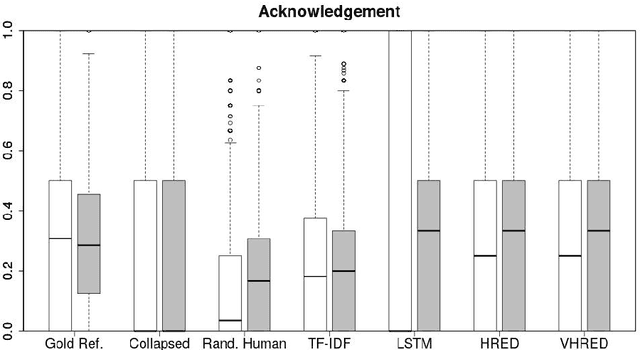

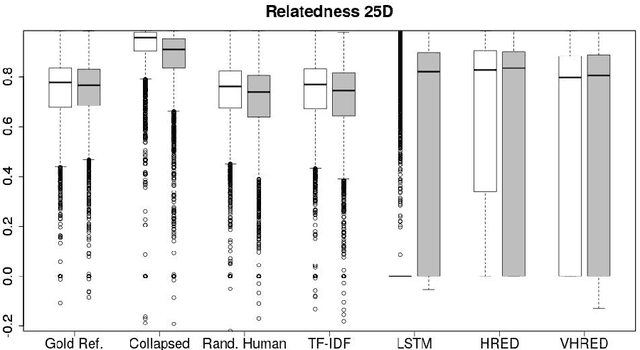
Automatically evaluating text-based, non-task-oriented dialogue systems (i.e., `chatbots') remains an open problem. Previous approaches have suffered challenges ranging from poor correlation with human judgment to poor generalization and have often required a gold standard reference for comparison or human-annotated data. Extending existing evaluation methods, we propose that a metric based on linguistic features may be able to maintain good correlation with human judgment and be interpretable, without requiring a gold-standard reference or human-annotated data. To support this proposition, we measure and analyze various linguistic features on dialogues produced by multiple dialogue models. We find that the features' behaviour is consistent with the known properties of the models tested, and is similar across domains. We also demonstrate that this approach exhibits promising properties such as zero-shot generalization to new domains on the related task of evaluating response relevance.