 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Integration of LinguisticFeatures into Statistical and Neural Machine Translation
Paper and Code
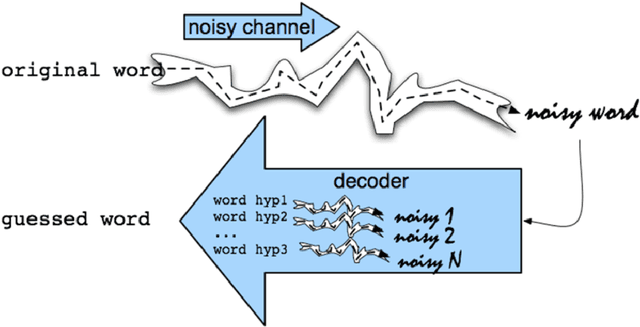

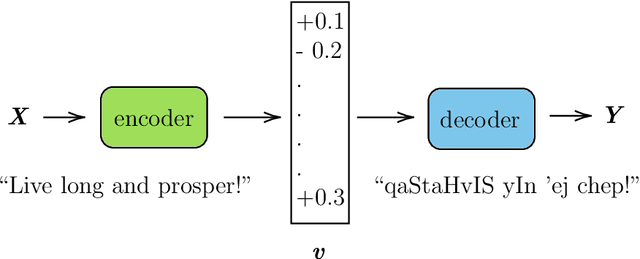
New machine translations (MT) technologies are emerging rapidly and with them, bold claims of achieving human parity such as: (i) the results produced approach "accuracy achieved by average bilingual human translators" (Wu et al., 2017b) or (ii) the "translation quality is at human parity when compared to professional human translators" (Hassan et al., 2018) have seen the light of day (Laubli et al., 2018). Aside from the fact that many of these papers craft their own definition of human parity, these sensational claims are often not supported by a complete analysis of all aspects involved in translation. Establishing the discrepancies between the strengths of statistical approaches to MT and the way humans translate has been the starting point of our research. By looking at MT output and linguistic theory, we were able to identify some remaining issues. The problems range from simple number and gender agreement errors to more complex phenomena such as the correct translation of aspectual values and tenses. Our experiments confirm, along with other studies (Bentivogli et al., 2016), that neural MT has surpassed statistical MT in many aspects. However, some problems remain and others have emerged. We cover a series of problems related to the integration of specific linguistic features into statistical and neural MT, aiming to analyse and provide a solution to some of them. Our work focuses on addressing three main research questions that revolve around the complex relationship between linguistics and MT in general. We identify linguistic information that is lacking in order for automatic translation systems to produce more accurate translations and integrate additional features into the existing pipelines. We identify overgeneralization or 'algorithmic bias' as a potential drawback of neural MT and link it to many of the remaining linguistic issues.