 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Importance of Contrastive Loss in Multimodal Learning
Paper and Code
Apr 07, 2023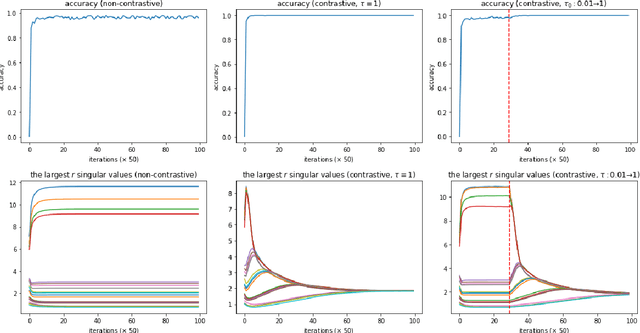

Recently, contrastive learning approaches (e.g., CLIP (Radford et al., 2021)) have received huge success in multimodal learning, where the model tries to minimize the distance between the representations of different views (e.g., image and its caption) of the same data point while keeping the representations of different data points away from each other. However, from a theoretical perspective, it is unclear how contrastive learning can learn the representations from different views efficiently, especially when the data is not isotropic. In this work, we analyze the training dynamics of a simple multimodal contrastive learning model and show that contrastive pairs are important for the model to efficiently balance the learned representations. In particular, we show that the positive pairs will drive the model to align the representations at the cost of increasing the condition number, while the negative pairs will reduce the condition number, keeping the learned representations balanced.