 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Efficacy of Adversarial Data Collection for Question Answering: Results from a Large-Scale Randomized Study
Paper and Code


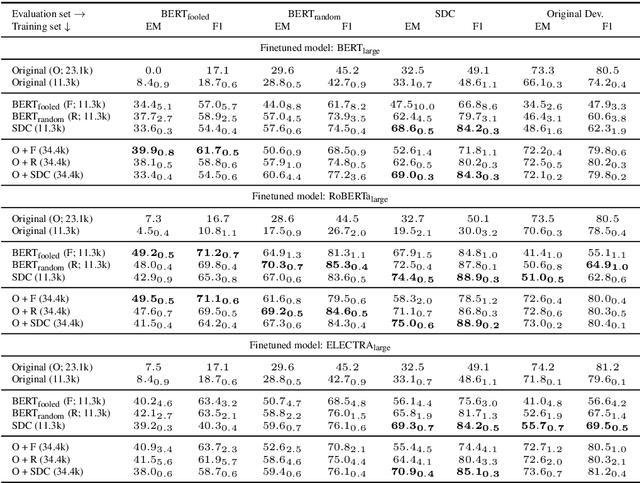

In adversarial data collection (ADC), a human workforce interacts with a model in real time, attempting to produce examples that elicit incorrect predictions. Researchers hope that models trained on these more challenging datasets will rely less on superficial patterns, and thus be less brittle. However, despite ADC's intuitive appeal, it remains unclear when training on adversarial datasets produces more robust models. In this paper, we conduct a large-scale controlled study focused on question answering, assigning workers at random to compose questions either (i) adversarially (with a model in the loop); or (ii) in the standard fashion (without a model). Across a variety of models and datasets, we find that models trained on adversarial data usually perform better on other adversarial datasets but worse on a diverse collection of out-of-domain evaluation sets. Finally, we provide a qualitative analysis of adversarial (vs standard) data, identifying key differences and offering guidance for future research.