 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn some studies of Fraud Detection Pipeline and related issues from the scope of Ensemble Learning and Graph-based Learning
Paper and Code
May 10, 2022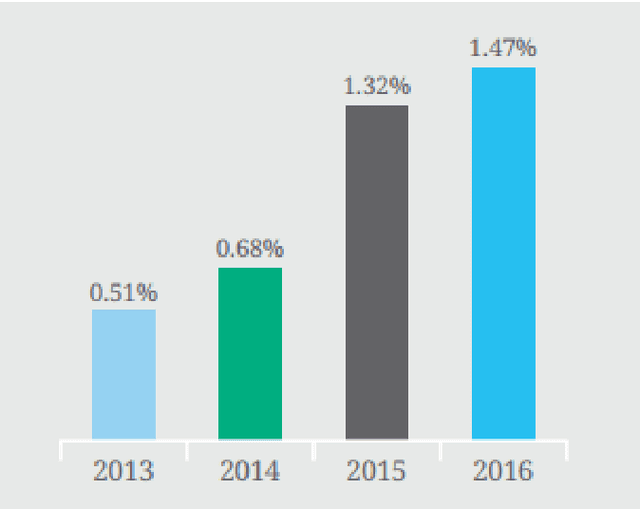
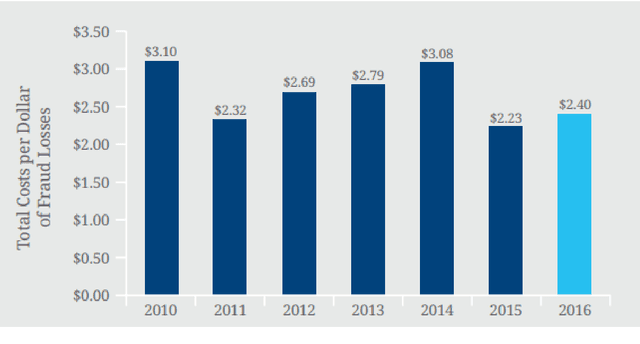
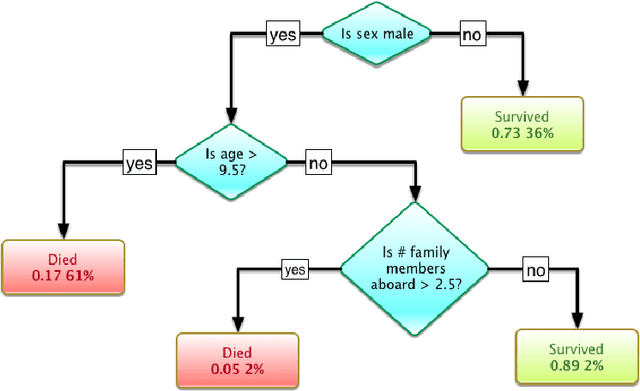
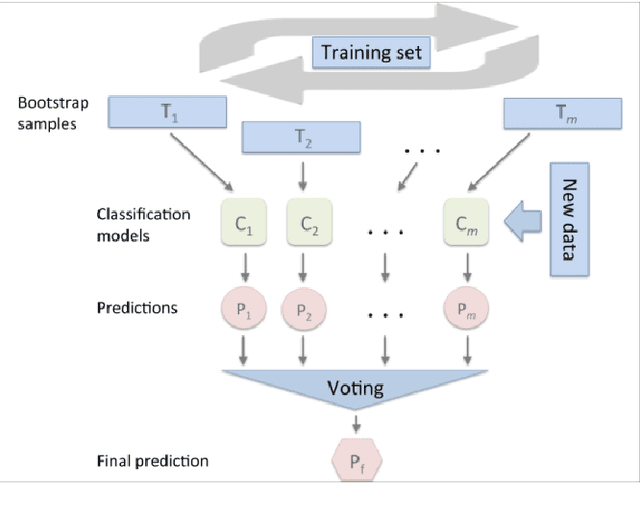
The UK anti-fraud charity Fraud Advisory Panel (FAP) in their review of 2016 estimates business costs of fraud at 144 billion, and its individual counterpart at 9.7 billion. Banking, insurance, manufacturing, and government are the most common industries affected by fraud activities. Designing an efficient fraud detection system could avoid losing the money; however, building this system is challenging due to many difficult problems, e.g.imbalanced data, computing costs, etc. Over the last three decades, there are various research relates to fraud detection but no agreement on what is the best approach to build the fraud detection system. In this thesis, we aim to answer some questions such as i) how to build a simplified and effective Fraud Detection System that not only easy to implement but also providing reliable results and our proposed Fraud Detection Pipeline is a potential backbone of the system and is easy to be extended or upgraded, ii) when to update models in our system (and keep the accuracy stable) in order to reduce the cost of updating process, iii) how to deal with an extreme imbalance in big data classification problem, e.g. fraud detection, since this is the gap between two difficult problems, iv) further, how to apply graph-based semi-supervised learning to detect fraudulent transactions.