 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn multi-token prediction for efficient LLM inference
Paper and Code
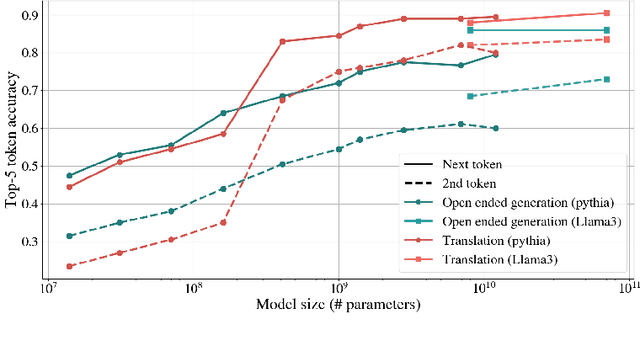
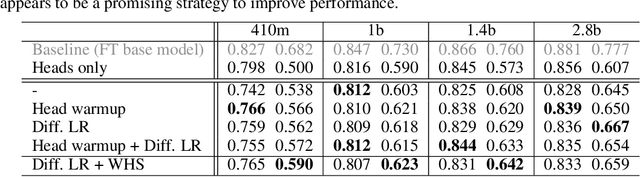
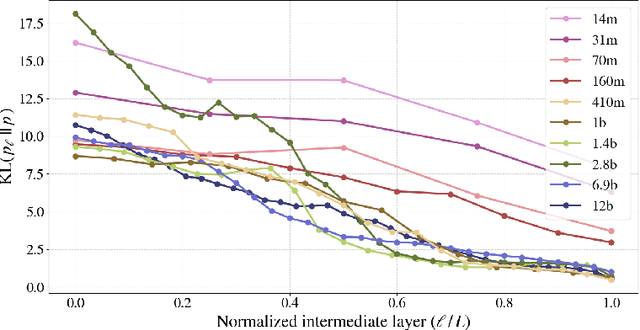
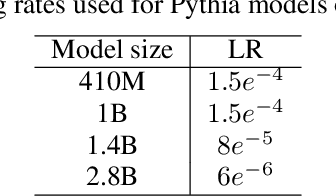
We systematically investigate multi-token prediction (MTP) capabilities within LLMs pre-trained for next-token prediction (NTP). We first show that such models inherently possess MTP capabilities via numerical marginalization over intermediate token probabilities, though performance is data-dependent and improves with model scale. Furthermore, we explore the challenges of integrating MTP heads into frozen LLMs and find that their hidden layers are strongly specialized for NTP, making adaptation non-trivial. Finally, we show that while joint training of MTP heads with the backbone improves performance, it cannot fully overcome this barrier, prompting further research in this direction. Our findings provide a deeper understanding of MTP applied to pretrained LLMs, informing strategies for accelerating inference through parallel token prediction.