 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Maximum Likelihood Training of Score-Based Generative Models
Paper and Code
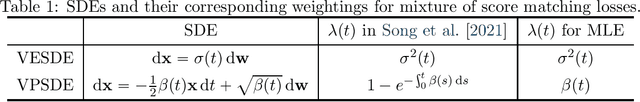
Score-based generative modeling has recently emerged as a promising alternative to traditional likelihood-based or implicit approaches. Learning in score-based models involves first perturbing data with a continuous-time stochastic process, and then matching the time-dependent gradient of the logarithm of the noisy data density - or score function - using a continuous mixture of score matching losses. In this note, we show that such an objective is equivalent to maximum likelihood for certain choices of mixture weighting. This connection provides a principled way to weight the objective function, and justifies its use for comparing different score-based generative models. Taken together with previous work, our result reveals that both maximum likelihood training and test-time log-likelihood evaluation can be achieved through parameterization of the score function alone, without the need to explicitly parameterize a density function.