 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Extreme Pruning of Random Forest Ensembles for Real-time Predictive Applications
Paper and Code
Mar 17, 2015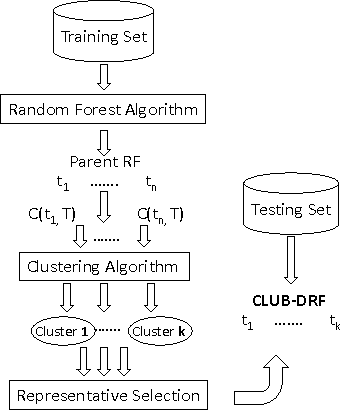
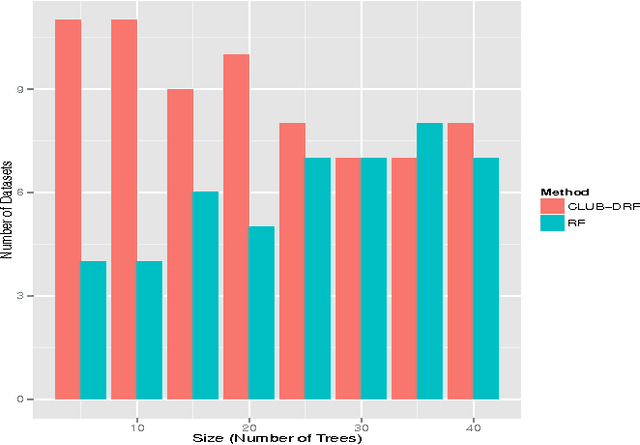
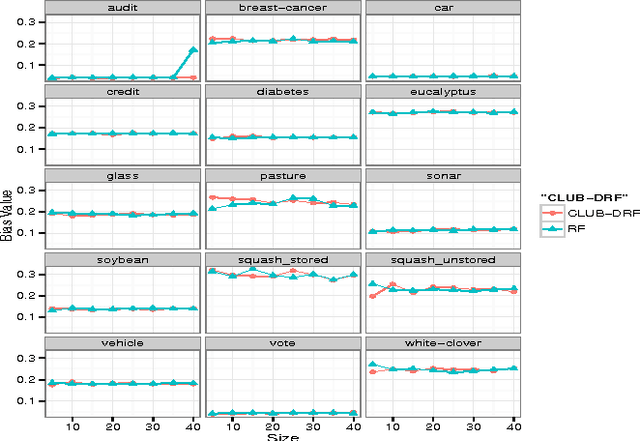
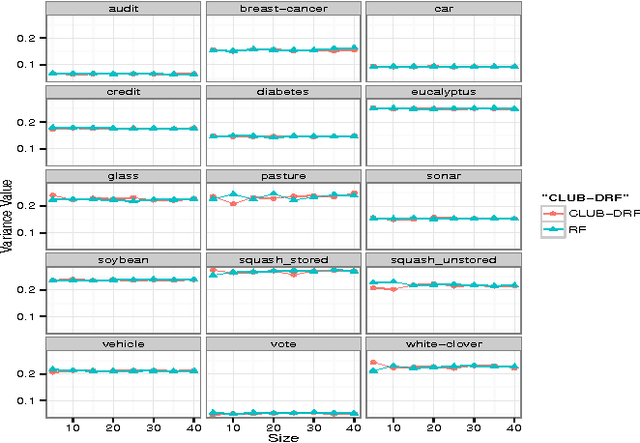
Random Forest (RF) is an ensemble supervised machine learning technique that was developed by Breiman over a decade ago. Compared with other ensemble techniques, it has proved its accuracy and superiority. Many researchers, however, believe that there is still room for enhancing and improving its performance accuracy. This explains why, over the past decade, there have been many extensions of RF where each extension employed a variety of techniques and strategies to improve certain aspect(s) of RF. Since it has been proven empiricallthat ensembles tend to yield better results when there is a significant diversity among the constituent models, the objective of this paper is twofold. First, it investigates how data clustering (a well known diversity technique) can be applied to identify groups of similar decision trees in an RF in order to eliminate redundant trees by selecting a representative from each group (cluster). Second, these likely diverse representatives are then used to produce an extension of RF termed CLUB-DRF that is much smaller in size than RF, and yet performs at least as good as RF, and mostly exhibits higher performance in terms of accuracy. The latter refers to a known technique called ensemble pruning. Experimental results on 15 real datasets from the UCI repository prove the superiority of our proposed extension over the traditional RF. Most of our experiments achieved at least 95% or above pruning level while retaining or outperforming the RF accuracy.