 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-Device Document Classification using multimodal features
Paper and Code
Jan 06, 2021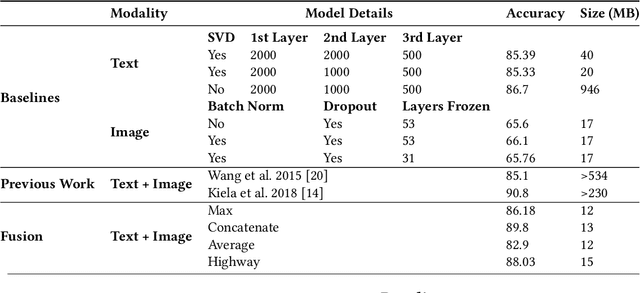
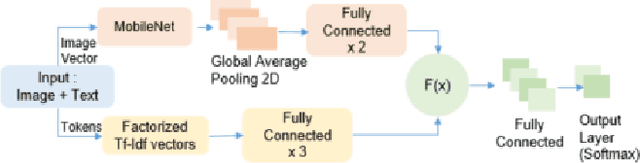

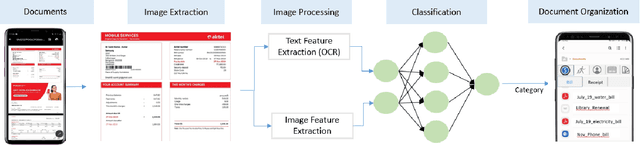
From small screenshots to large videos, documents take up a bulk of space in a modern smartphone. Documents in a phone can accumulate from various sources, and with the high storage capacity of mobiles, hundreds of documents are accumulated in a short period. However, searching or managing documents remains an onerous task, since most search methods depend on meta-information or only text in a document. In this paper, we showcase that a single modality is insufficient for classification and present a novel pipeline to classify documents on-device, thus preventing any private user data transfer to server. For this task, we integrate an open-source library for Optical Character Recognition (OCR) and our novel model architecture in the pipeline. We optimise the model for size, a necessary metric for on-device inference. We benchmark our classification model with a standard multimodal dataset FOOD-101 and showcase competitive results with the previous State of the Art with 30% model compression.