 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Buggy Resizing Libraries and Surprising Subtleties in FID Calculation
Paper and Code
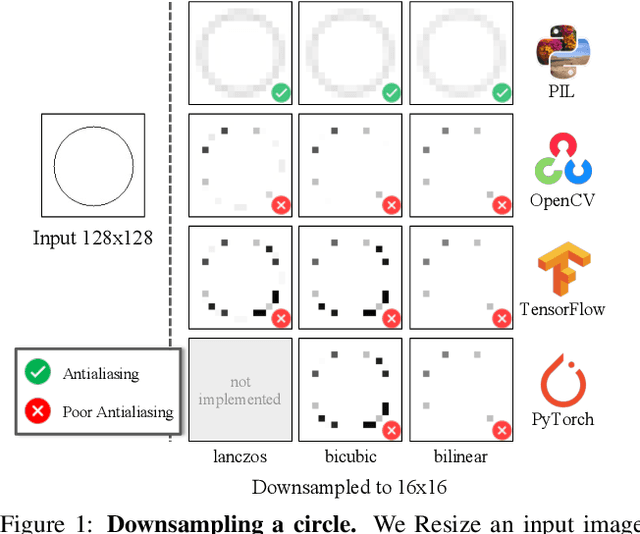
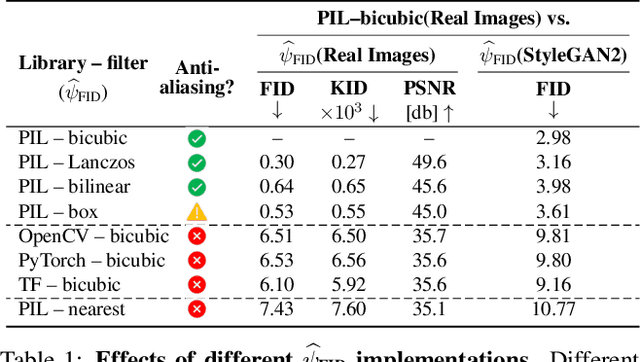
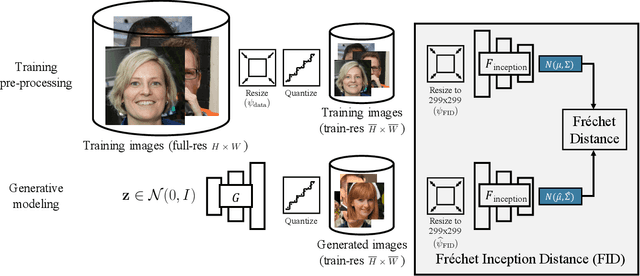
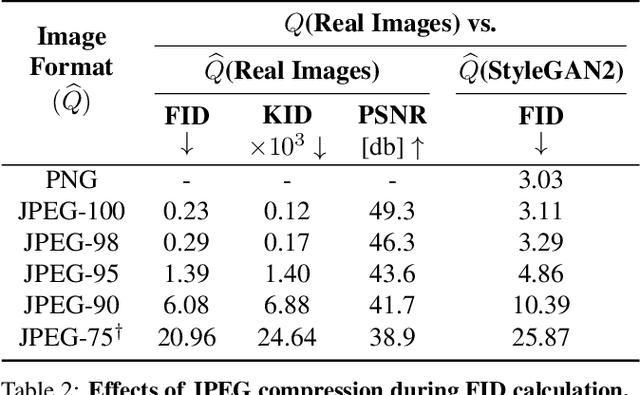
We investigate the sensitivity of the Fr\'echet Inception Distance (FID) score to inconsistent and often incorrect implementations across different image processing libraries. FID score is widely used to evaluate generative models, but each FID implementation uses a different low-level image processing process. Image resizing functions in commonly-used deep learning libraries often introduce aliasing artifacts. We observe that numerous subtle choices need to be made for FID calculation and a lack of consistencies in these choices can lead to vastly different FID scores. In particular, we show that the following choices are significant: (1) selecting what image resizing library to use, (2) choosing what interpolation kernel to use, (3) what encoding to use when representing images. We additionally outline numerous common pitfalls that should be avoided and provide recommendations for computing the FID score accurately. We provide an easy-to-use optimized implementation of our proposed recommendations in the accompanying code.