 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObservable adjustments in single-index models for regularized M-estimators
Paper and Code
Apr 14, 2022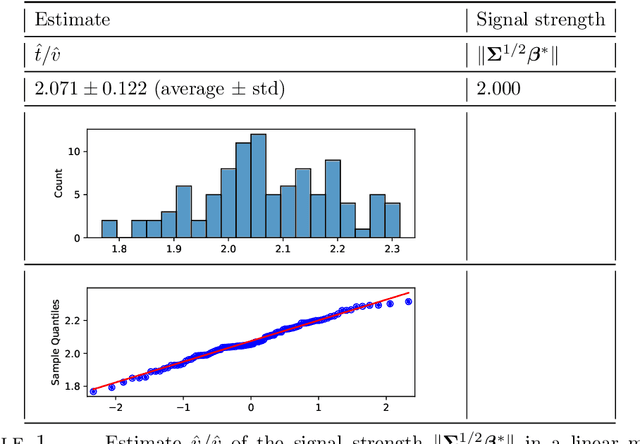

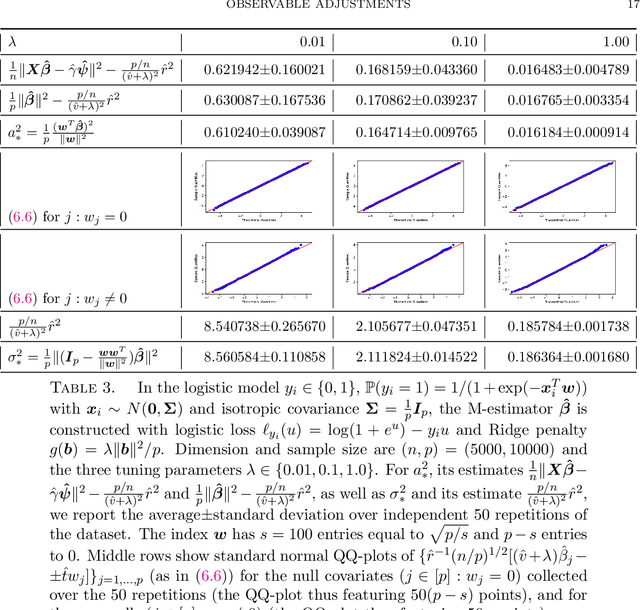
We consider observations $(X,y)$ from single index models with unknown link function, Gaussian covariates and a regularized M-estimator $\hat\beta$ constructed from convex loss function and regularizer. In the regime where sample size $n$ and dimension $p$ are both increasing such that $p/n$ has a finite limit, the behavior of the empirical distribution of $\hat\beta$ and the predicted values $X\hat\beta$ has been previously characterized in a number of models: The empirical distributions are known to converge to proximal operators of the loss and penalty in a related Gaussian sequence model, which captures the interplay between ratio $p/n$, loss, regularization and the data generating process. This connection between$(\hat\beta,X\hat\beta)$ and the corresponding proximal operators require solving fixed-point equations that typically involve unobservable quantities such as the prior distribution on the index or the link function. This paper develops a different theory to describe the empirical distribution of $\hat\beta$ and $X\hat\beta$: Approximations of $(\hat\beta,X\hat\beta)$ in terms of proximal operators are provided that only involve observable adjustments. These proposed observable adjustments are data-driven, e.g., do not require prior knowledge of the index or the link function. These new adjustments yield confidence intervals for individual components of the index, as well as estimators of the correlation of $\hat\beta$ with the index. The interplay between loss, regularization and the model is thus captured in a data-driven manner, without solving the fixed-point equations studied in previous works. The results apply to both strongly convex regularizers and unregularized M-estimation. Simulations are provided for the square and logistic loss in single index models including logistic regression and 1-bit compressed sensing with 20\% corrupted bits.