 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNode discovery in a networked organization
Paper and Code
Jun 26, 2009

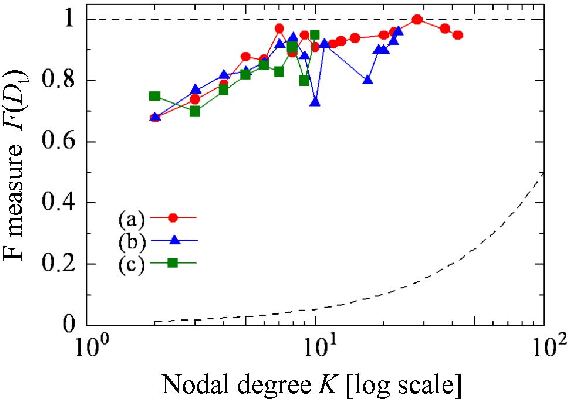
In this paper, I present a method to solve a node discovery problem in a networked organization. Covert nodes refer to the nodes which are not observable directly. They affect social interactions, but do not appear in the surveillance logs which record the participants of the social interactions. Discovering the covert nodes is defined as identifying the suspicious logs where the covert nodes would appear if the covert nodes became overt. A mathematical model is developed for the maximal likelihood estimation of the network behind the social interactions and for the identification of the suspicious logs. Precision, recall, and F measure characteristics are demonstrated with the dataset generated from a real organization and the computationally synthesized datasets. The performance is close to the theoretical limit for any covert nodes in the networks of any topologies and sizes if the ratio of the number of observation to the number of possible communication patterns is large.