 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNew Faithfulness-Centric Interpretability Paradigms for Natural Language Processing
Paper and Code
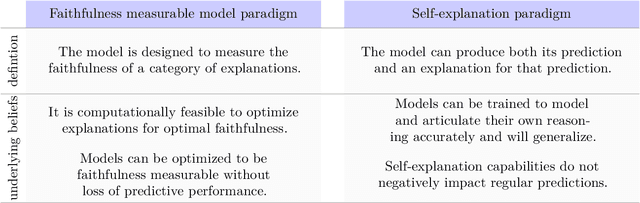
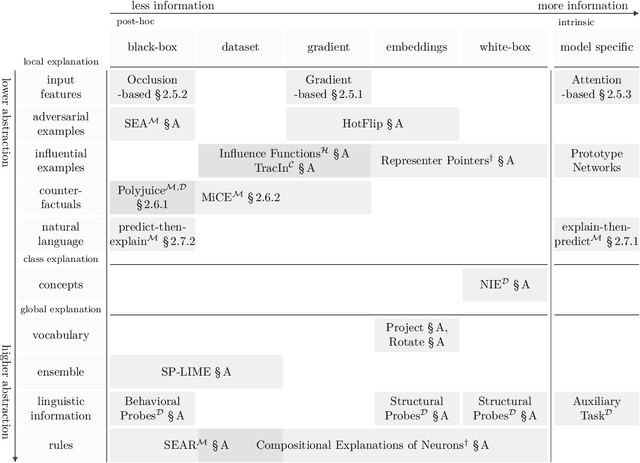


As machine learning becomes more widespread and is used in more critical applications, it's important to provide explanations for these models, to prevent unintended behavior. Unfortunately, many current interpretability methods struggle with faithfulness. Therefore, this Ph.D. thesis investigates the question "How to provide and ensure faithful explanations for complex general-purpose neural NLP models?" The main thesis is that we should develop new paradigms in interpretability. This is achieved by first developing solid faithfulness metrics and then applying the lessons learned from this investigation to develop new paradigms. The two new paradigms explored are faithfulness measurable models (FMMs) and self-explanations. The idea in self-explanations is to have large language models explain themselves, we identify that current models are not capable of doing this consistently. However, we suggest how this could be achieved. The idea of FMMs is to create models that are designed such that measuring faithfulness is cheap and precise. This makes it possible to optimize an explanation towards maximum faithfulness, which makes FMMs designed to be explained. We find that FMMs yield explanations that are near theoretical optimal in terms of faithfulness. Overall, from all investigations of faithfulness, results show that post-hoc and intrinsic explanations are by default model and task-dependent. However, this was not the case when using FMMs, even with the same post-hoc explanation methods. This shows, that even simple modifications to the model, such as randomly masking the training dataset, as was done in FMMs, can drastically change the situation and result in consistently faithful explanations. This answers the question of how to provide and ensure faithful explanations.