 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Word Search in Historical Manuscript Collections
Paper and Code


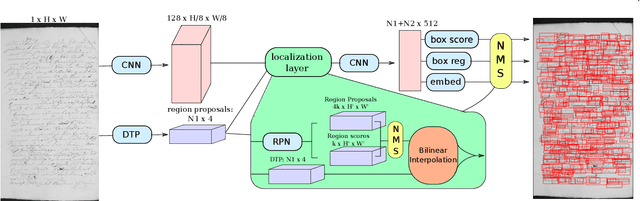

We address the problem of segmenting and retrieving word images in collections of historical manuscripts given a text query. This is commonly referred to as "word spotting". To this end, we first propose an end-to-end trainable model based on deep neural networks that we dub Ctrl-F-Net. The model simultaneously generates region proposals and embeds them into a word embedding space, wherein a search is performed. We further introduce a simplified version called Ctrl-F-Mini. It is faster with similar performance, though it is limited to more easily segmented manuscripts. We evaluate both models on common benchmark datasets and surpass the previous state of the art. Finally, in collaboration with historians, we employ the Ctrl-F-Net to search within a large manuscript collection of over 100 thousand pages, written across two centuries. With only 11 training pages, we enable large scale data collection in manuscript-based historical research. This results in a speed up of data collection and the number of manuscripts processed by orders of magnitude. Given the time consuming manual work required to study old manuscripts in the humanities, quick and robust tools for word spotting has the potential to revolutionise domains like history, religion and language.