 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNested and Balanced Entity Recognition using Multi-Task Learning
Paper and Code
Jun 11, 2021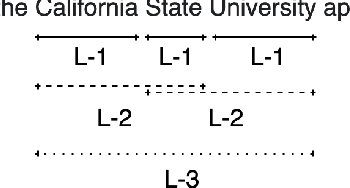
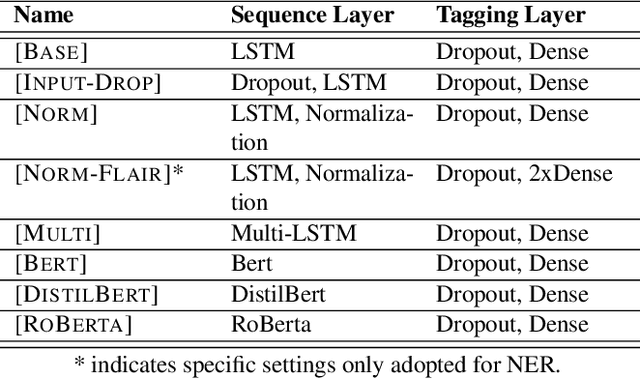
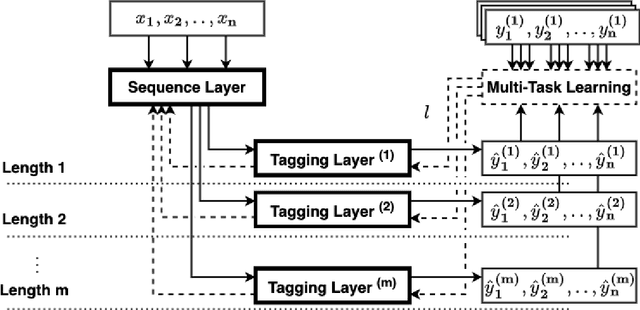
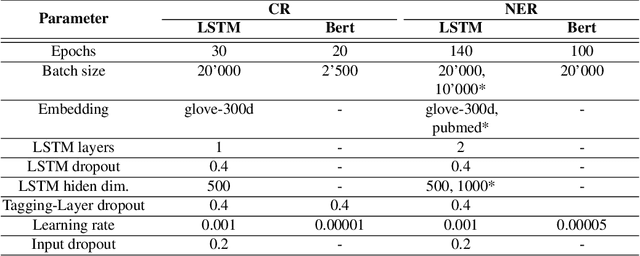
Entity Recognition (ER) within a text is a fundamental exercise in Natural Language Processing, enabling further depending tasks such as Knowledge Extraction, Text Summarisation, or Keyphrase Extraction. An entity consists of single words or of a consecutive sequence of terms, constituting the basic building blocks for communication. Mainstream ER approaches are mainly limited to flat structures, concentrating on the outermost entities while ignoring the inner ones. This paper introduces a partly-layered network architecture that deals with the complexity of overlapping and nested cases. The proposed architecture consists of two parts: (1) a shared Sequence Layer and (2) a stacked component with multiple Tagging Layers. The adoption of such an architecture has the advantage of preventing overfit to a specific word-length, thus maintaining performance for longer entities despite their lower frequency. To verify the proposed architecture's effectiveness, we train and evaluate this architecture to recognise two kinds of entities - Concepts (CR) and Named Entities (NER). Our approach achieves state-of-the-art NER performances, while it outperforms previous CR approaches. Considering these promising results, we see the possibility to evolve the architecture for other cases such as the extraction of events or the detection of argumentative components.