 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNarrative Trails: A Method for Coherent Storyline Extraction via Maximum Capacity Path Optimization
Paper and Code


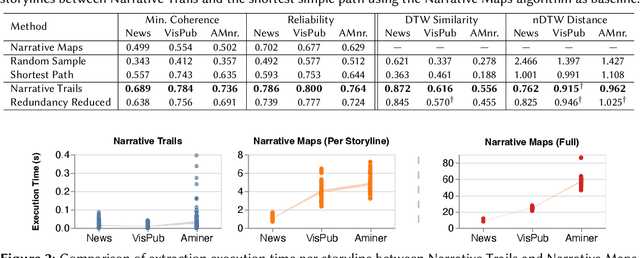

Traditional information retrieval is primarily concerned with finding relevant information from large datasets without imposing a structure within the retrieved pieces of data. However, structuring information in the form of narratives--ordered sets of documents that form coherent storylines--allows us to identify, interpret, and share insights about the connections and relationships between the ideas presented in the data. Despite their significance, current approaches for algorithmically extracting storylines from data are scarce, with existing methods primarily relying on intricate word-based heuristics and auxiliary document structures. Moreover, many of these methods are difficult to scale to large datasets and general contexts, as they are designed to extract storylines for narrow tasks. In this paper, we propose Narrative Trails, an efficient, general-purpose method for extracting coherent storylines in large text corpora. Specifically, our method uses the semantic-level information embedded in the latent space of deep learning models to build a sparse coherence graph and extract narratives that maximize the minimum coherence of the storylines. By quantitatively evaluating our proposed methods on two distinct narrative extraction tasks, we show the generalizability and scalability of Narrative Trails in multiple contexts while also simplifying the extraction pipeline.