 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiSV: Dataset for Far-Field Multi-Channel Speaker Verification
Paper and Code

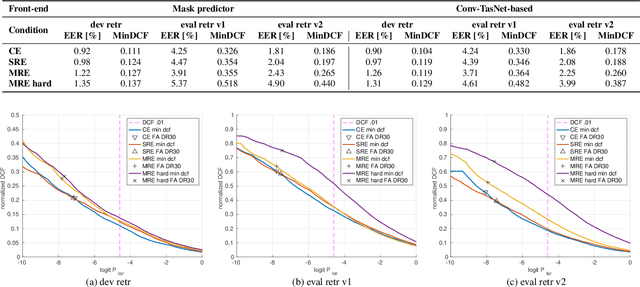
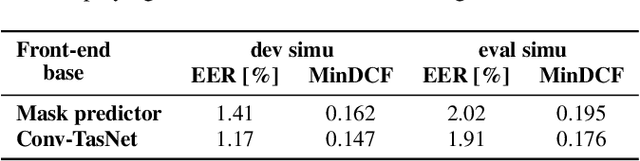
Motivated by unconsolidated data situation and the lack of a standard benchmark in the field, we complement our previous efforts and present a comprehensive corpus designed for training and evaluating text-independent multi-channel speaker verification systems. It can be readily used also for experiments with dereverberation, denoising, and speech enhancement. We tackled the ever-present problem of the lack of multi-channel training data by utilizing data simulation on top of clean parts of the Voxceleb dataset. The development and evaluation trials are based on a retransmitted Voices Obscured in Complex Environmental Settings (VOiCES) corpus, which we modified to provide multi-channel trials. We publish full recipes that create the dataset from public sources as the MultiSV corpus, and we provide results with two of our multi-channel speaker verification systems with neural network-based beamforming based either on predicting ideal binary masks or the more recent Conv-TasNet.