 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultidimensional Scaling for Gene Sequence Data with Autoencoders
Paper and Code
Apr 19, 2021
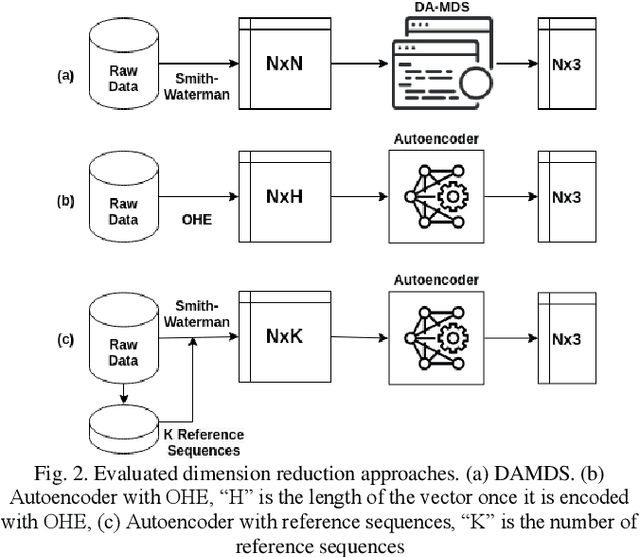
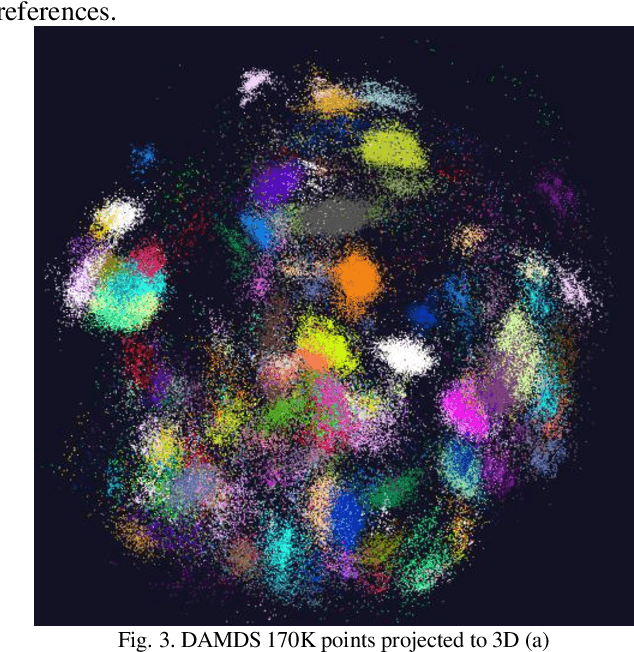

Multidimensional scaling of gene sequence data has long played a vital role in analysing gene sequence data to identify clusters and patterns. However the computation complexities and memory requirements of state-of-the-art dimensional scaling algorithms make it infeasible to scale to large datasets. In this paper we present an autoencoder-based dimensional reduction model which can easily scale to datasets containing millions of gene sequences, while attaining results comparable to state-of-the-art MDS algorithms with minimal resource requirements. The model also supports out-of-sample data points with a 99.5%+ accuracy based on our experiments. The proposed model is evaluated against DAMDS with a real world fungi gene sequence dataset. The presented results showcase the effectiveness of the autoencoder-based dimension reduction model and its advantages.