 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Stereo Network with attention thin volume
Paper and Code
Oct 16, 2021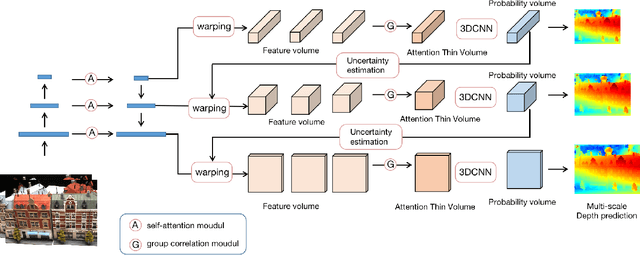



We propose an efficient multi-view stereo (MVS) network for infering depth value from multiple RGB images. Recent studies have shown that mapping the geometric relationship in real space to neural network is an essential topic of the MVS problem. Specifically, these methods focus on how to express the correspondence between different views by constructing a nice cost volume. In this paper, we propose a more complete cost volume construction approach based on absorbing previous experience. First of all, we introduce the self-attention mechanism to fully aggregate the dominant information from input images and accurately model the long-range dependency, so as to selectively aggregate reference features. Secondly, we introduce the group-wise correlation to feature aggregation, which greatly reduces the memory and calculation burden. Meanwhile, this method enhances the information interaction between different feature channels. With this approach, a more lightweight and efficient cost volume is constructed. Finally we follow the coarse to fine strategy and refine the depth sampling range scale by scale with the help of uncertainty estimation. We further combine the previous steps to get the attention thin volume. Quantitative and qualitative experiments are presented to demonstrate the performance of our model.