 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-timescale representation learning in LSTM Language Models
Paper and Code
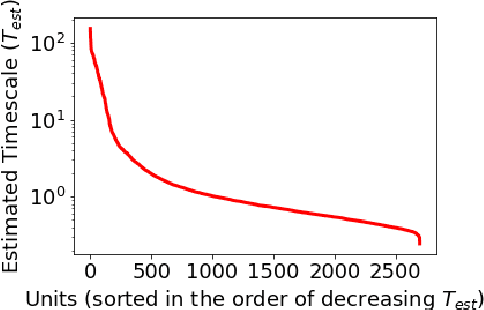
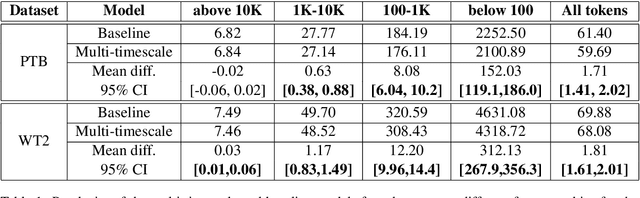
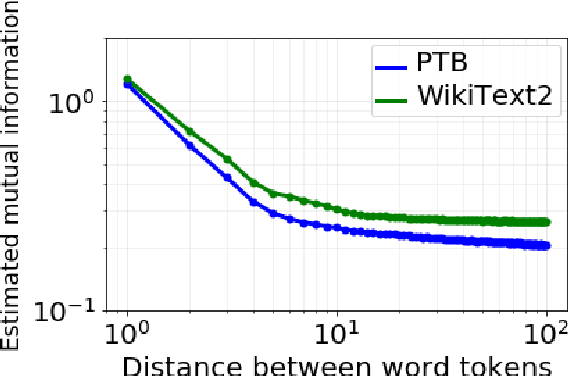

Although neural language models are effective at capturing statistics of natural language, their representations are challenging to interpret. In particular, it is unclear how these models retain information over multiple timescales. In this work, we construct explicitly multi-timescale language models by manipulating the input and forget gate biases in a long short-term memory (LSTM) network. The distribution of timescales is selected to approximate power law statistics of natural language through a combination of exponentially decaying memory cells. We then empirically analyze the timescale of information routed through each part of the model using word ablation experiments and forget gate visualizations. These experiments show that the multi-timescale model successfully learns representations at the desired timescales, and that the distribution includes longer timescales than a standard LSTM. Further, information about high-,mid-, and low-frequency words is routed preferentially through units with the appropriate timescales. Thus we show how to construct language models with interpretable representations of different information timescales.