 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-scale Graph Convolutional Networks with Self-Attention
Paper and Code
Dec 04, 2021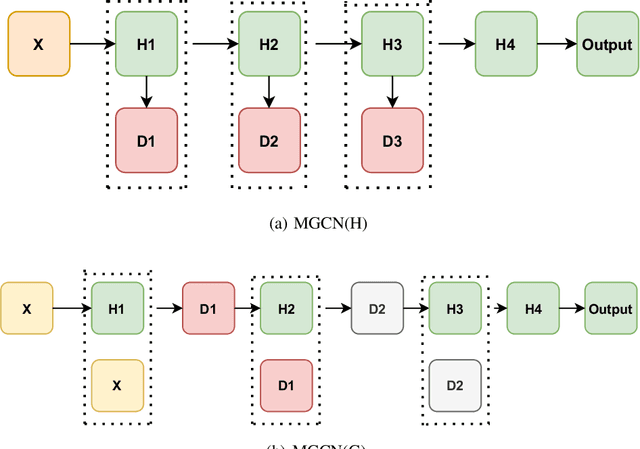


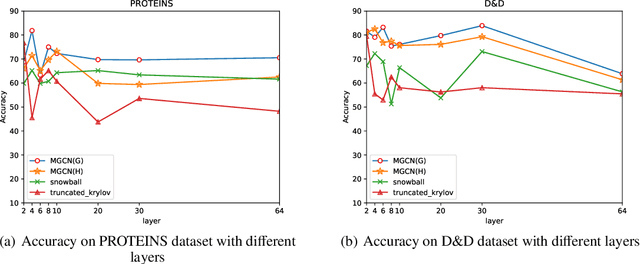
Graph convolutional networks (GCNs) have achieved remarkable learning ability for dealing with various graph structural data recently. In general, deep GCNs do not work well since graph convolution in conventional GCNs is a special form of Laplacian smoothing, which makes the representation of different nodes indistinguishable. In the literature, multi-scale information was employed in GCNs to enhance the expressive power of GCNs. However, over-smoothing phenomenon as a crucial issue of GCNs remains to be solved and investigated. In this paper, we propose two novel multi-scale GCN frameworks by incorporating self-attention mechanism and multi-scale information into the design of GCNs. Our methods greatly improve the computational efficiency and prediction accuracy of the GCNs model. Extensive experiments on both node classification and graph classification demonstrate the effectiveness over several state-of-the-art GCNs. Notably, the proposed two architectures can efficiently mitigate the over-smoothing problem of GCNs, and the layer of our model can even be increased to $64$.