 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Learning for AU Detection Based on Multi-Head Fused Transformers
Paper and Code
Mar 22, 2022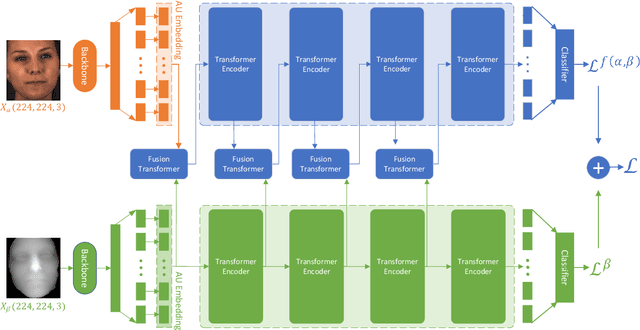
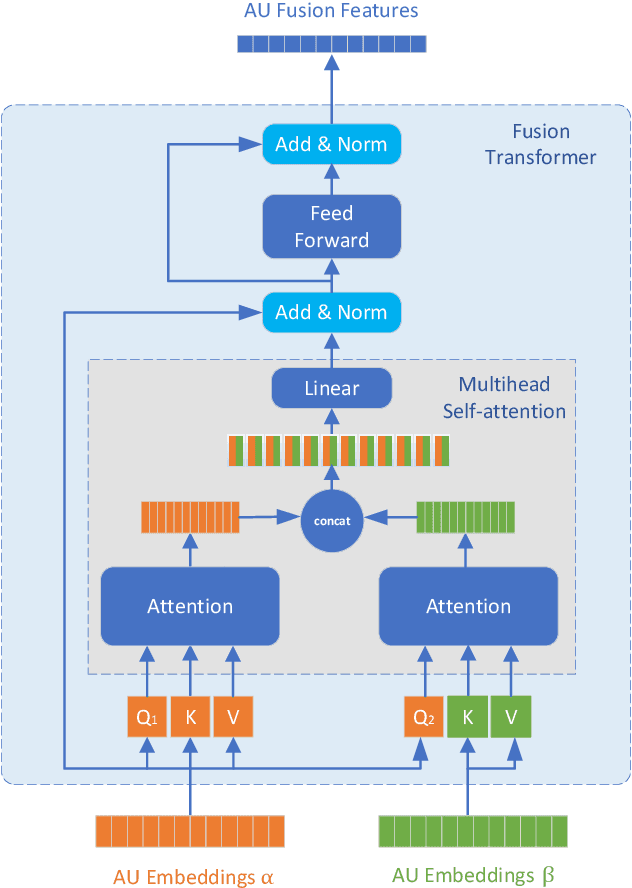
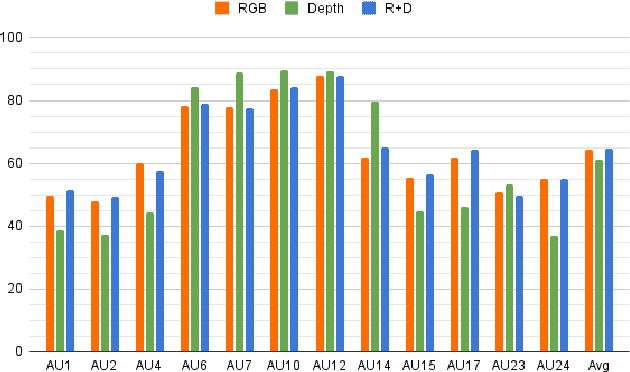
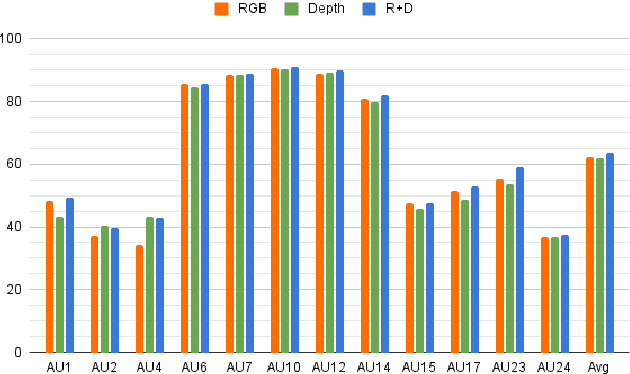
Multi-modal learning has been intensified in recent years, especially for applications in facial analysis and action unit detection whilst there still exist two main challenges in terms of 1) relevant feature learning for representation and 2) efficient fusion for multi-modalities. Recently, there are a number of works have shown the effectiveness in utilizing the attention mechanism for AU detection, however, most of them are binding the region of interest (ROI) with features but rarely apply attention between features of each AU. On the other hand, the transformer, which utilizes a more efficient self-attention mechanism, has been widely used in natural language processing and computer vision tasks but is not fully explored in AU detection tasks. In this paper, we propose a novel end-to-end Multi-Head Fused Transformer (MFT) method for AU detection, which learns AU encoding features representation from different modalities by transformer encoder and fuses modalities by another fusion transformer module. Multi-head fusion attention is designed in the fusion transformer module for the effective fusion of multiple modalities. Our approach is evaluated on two public multi-modal AU databases, BP4D, and BP4D+, and the results are superior to the state-of-the-art algorithms and baseline models. We further analyze the performance of AU detection from different modalities.