 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Layer Softmaxing during Training Neural Machine Translation for Flexible Decoding with Fewer Layers
Paper and Code

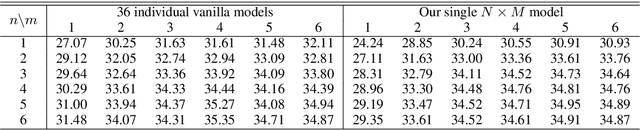


This paper proposes a novel procedure for training an encoder-decoder based deep neural network which compresses NxM models into a single model enabling us to dynamically choose the number of encoder and decoder layers for decoding. Usually, the output of the last layer of the N-layer encoder is fed to the M-layer decoder, and the output of the last decoder layer is used to compute softmax loss. Instead, our method computes a single loss consisting of NxM losses: the softmax loss for the output of each of the M decoder layers derived using the output of each of the N encoder layers. A single model trained by our method can be used for decoding with an arbitrary fewer number of encoder and decoder layers. In practical scenarios, this (a) enables faster decoding with insignificant losses in translation quality and (b) alleviates the need to train NxM models, thereby saving space. We take a case study of neural machine translation and show the advantage and give a cost-benefit analysis of our approach.