 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Dimensional Model Compression of Vision Transformer
Paper and Code
Dec 31, 2021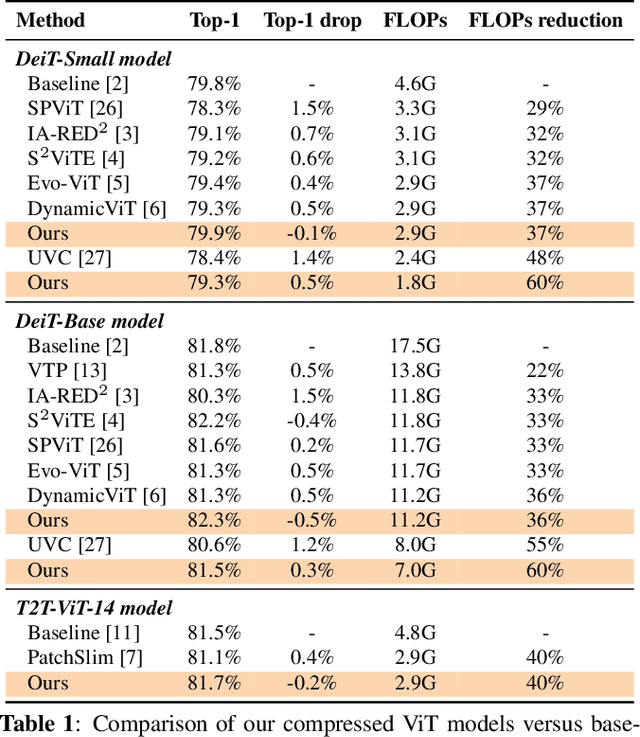
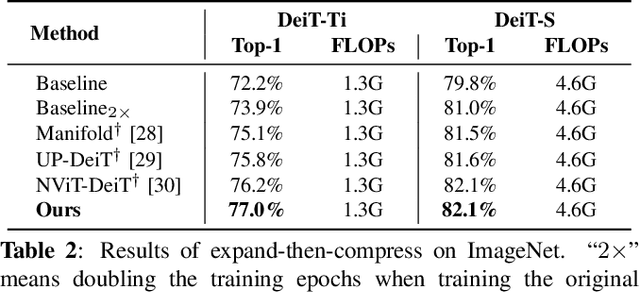


Vision transformers (ViT) have recently attracted considerable attentions, but the huge computational cost remains an issue for practical deployment. Previous ViT pruning methods tend to prune the model along one dimension solely, which may suffer from excessive reduction and lead to sub-optimal model quality. In contrast, we advocate a multi-dimensional ViT compression paradigm, and propose to harness the redundancy reduction from attention head, neuron and sequence dimensions jointly. We firstly propose a statistical dependence based pruning criterion that is generalizable to different dimensions for identifying deleterious components. Moreover, we cast the multi-dimensional compression as an optimization, learning the optimal pruning policy across the three dimensions that maximizes the compressed model's accuracy under a computational budget. The problem is solved by our adapted Gaussian process search with expected improvement. Experimental results show that our method effectively reduces the computational cost of various ViT models. For example, our method reduces 40\% FLOPs without top-1 accuracy loss for DeiT and T2T-ViT models, outperforming previous state-of-the-arts.