 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocular Depth Estimation: A Survey
Paper and Code
Jan 27, 2019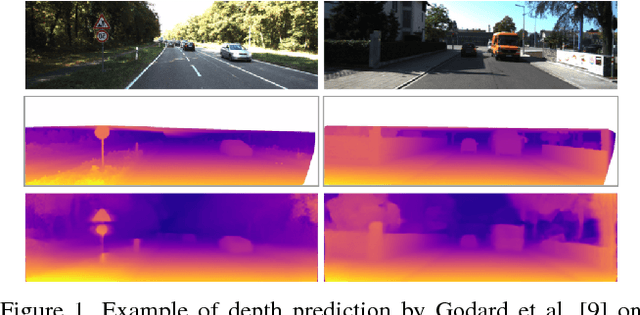


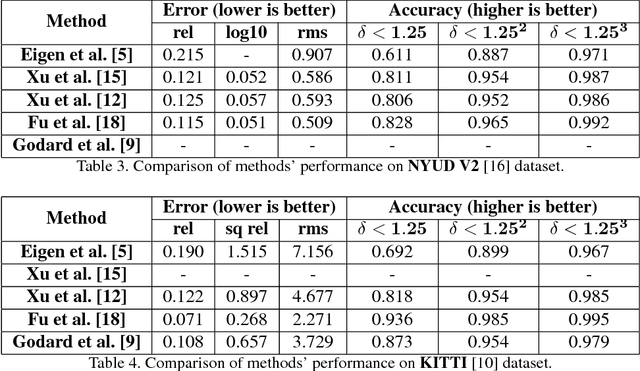
Monocular depth estimation is often described as an ill-posed and inherently ambiguous problem. Estimating depth from 2D images is a crucial step in scene reconstruction, 3Dobject recognition, segmentation, and detection. The problem can be framed as: given a single RGB image as input, predict a dense depth map for each pixel. This problem is worsened by the fact that most scenes have large texture and structural variations, object occlusions, and rich geometric detailing. All these factors contribute to difficulty in accurate depth estimation. In this paper, we review five papers that attempt to solve the depth estimation problem with various techniques including supervised, weakly-supervised, and unsupervised learning techniques. We then compare these papers and understand the improvements made over one another. Finally, we explore potential improvements that can aid to better solve this problem.