 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoMo: A shared encoder Model for text, image and multi-Modal representations
Paper and Code
Apr 11, 2023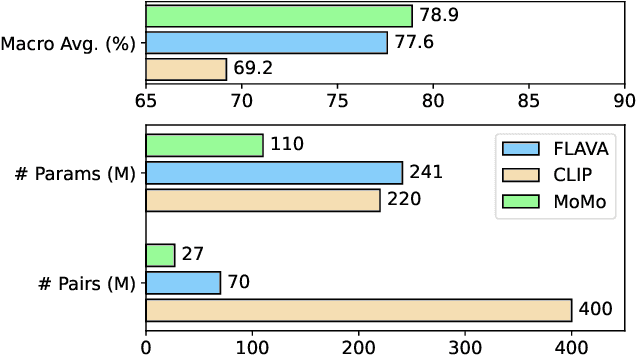
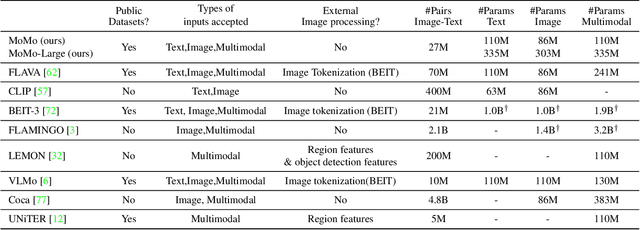
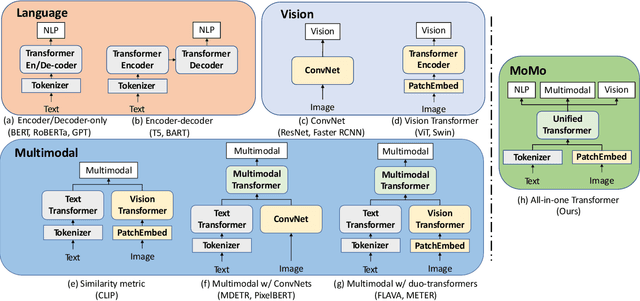

We propose a self-supervised shared encoder model that achieves strong results on several visual, language and multimodal benchmarks while being data, memory and run-time efficient. We make three key contributions. First, in contrast to most existing works, we use a single transformer with all the encoder layers processing both the text and the image modalities. Second, we propose a stage-wise training strategy where the model is first trained on images, then jointly with unimodal text and image datasets and finally jointly with text and text-image datasets. Third, to preserve information across both the modalities, we propose a training pipeline that learns simultaneously from gradient updates of different modalities at each training update step. The results on downstream text-only, image-only and multimodal tasks show that our model is competitive with several strong models while using fewer parameters and lesser pre-training data. For example, MoMo performs competitively with FLAVA on multimodal (+3.1), image-only (+1.1) and text-only (-0.1) tasks despite having 2/5th the number of parameters and using 1/3rd the image-text training pairs. Finally, we ablate various design choices and further show that increasing model size produces significant performance gains indicating potential for substantial improvements with larger models using our approach.